Semi Integration and Differentiation
The main part of the ec-tools package are the implemented numerical semi integration (or differentiation) algorithms. The following section describes the underlying principles and algorithms, based on literature of Oldham [3, 4] and Pajkossy [5]. The second section provides information about how to work with the algorithms. In the third section, the different algorithms are tested for accuracy, functionality and (time) performance.
Fundamentals
The differentiation and the integration are common mathematical operations. The differentiation of an arbitrary function is often expressed by \(\frac{\mathrm{d}}{\mathrm{d}x} f(x)\). Interestingly, the integration can also be defined in a similar way:
Here it must be considered that a lower limit must be defined so that the integral is completely defined. These operations can be then displayed in a more general way by:
With:
\(v= 1\): Differentiation
\(v=-1\): Integration
The so-called semi-operators are \(v=\frac{1}{2}\) for semi differentiation and \(v=-\frac{1}{2}\) for semi integration. The following figure visualizes the idea of semi integration and semi differentiation.
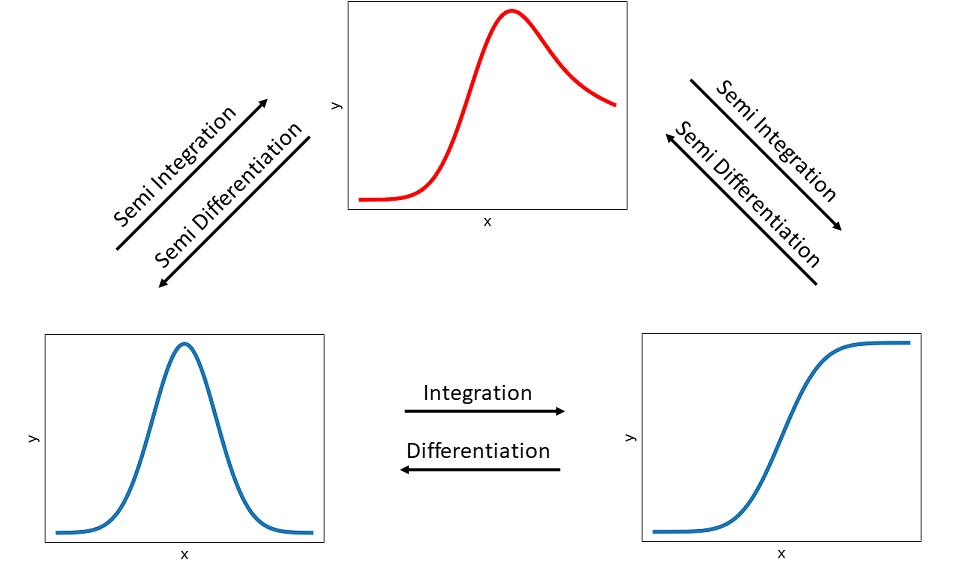
A semi integration of a peak function (bottom left) results in a hybrid function (top) and by applying another semi integration it is transformed into a wave-like function (bottom right), which is equal to performing a regular integration of the peak function. The operations in opposite direction are analog, except that semi differentiations and a regular differentiation are performed, respectively.
Semi Integration Methods
Several methods exist for applying semi integration and semi differentiation, respectively. These computations generally need discrete values, i.e. the function graph (see above) has to be seperated into discrete finite values:
It is assumed that the step size \(\delta\) is equidistant, meaning for a fixed set of x-Values N:
The following algorithms (Gruenwald and Riemann & Liouville) are taken from Oldham in [4] and the fast Riemann from Pajkossy et. al. in [5].
Gruenwald Algorithms
One method of semi integration was introduced by Gruenwald [2] and Oldham shows in his web ressource 1244 from [3] how this type of semi integration can be applied as an algorithm, called G1.
It can be generally expressed by the sum of the discrete function values multiplied with weights \(w_n\) divided by the stepsize:
The G1 algorithm is ideal for (cyclic) voltammograms, where the early signals are small. Note, that these algorithms are less suitable for step and pulse techniques, in which the initial currents are large [3].
The weights can be expressed in different ways. The single weights \(w_n\) often depend on their predecessor \(w_{n-1}\). As the factorial expression could lead to an computive intensive overflow, this algorithm needs to be simplified.
The Gruenwald G1 semi integration algorithm is defined as follows:
Which can be also displayed in reverse summation to allow a more efficient implementation:
With:
\(w_0 = 1\)
\(w_n = \frac{(n-0.5)w_{n-1}}{n} = (1-\frac{0.5}{n})w_{n-1}\)
The previous definition can also be applied as Gruenwald G1 semi differentiation algorithm with some changes:
With:
\(w_0 = 1\)
\(w_n = \frac{(n-1.5)w_{n-1}}{n}\)
Riemann and Liouville Algorithms
Another method to determine the semi integral was introduced by Riemann and Liouville [1] and described by Oldham in [3] as R1 algorithm in his web ressource 1244. These sort of algorithms are mainly straightforward general-purpose algorithms.
The algorithm for the R1 semi integration is defined by:
Similar to the G1 algorithm is the R1 for semi integration and semi differentiation. But it is not usable for application to currents that arise from potential steps or leaps [3], as:
The large current at \(t=0\), immediately following the step is impossible to measure accurately and even if it would be possible, it is likely to be largely composed of a chemically uninteresting non-faradaic component. But the algorithm still requires a value of \(f(0)\).
The algorithm is based on the assumption that \(f(t)\) can be treated as an assemblage of linear segments, whereas faradaic currents arising from a potential step and are non-linear with time.
The general definition for the R1 semi differentiation is:
Fast Riemann
The following algorithm was introduced by Pajkossy et al. in 1984 [5] and is based on the Riemann-Liouville transformation (RLT). Its big advantage is, that the computation time increases only linearly with the number of points (\(N\)). Here it is necessary to define some input variables (besides \(t\) and \(I(t)\) data), where \(q\) is equal to \(v\), describing a semi integration or semi differentiation. \(\delta_t\) defines the constant time intervall (i.e. \(t_2 - t_1\)) and \(c_1, c_2\) are constant values, which is set to \(c_1=8, c_2=2\) by default, as recommended by Pajkossy. With these variables, the algorithm can be described as pseudo code:
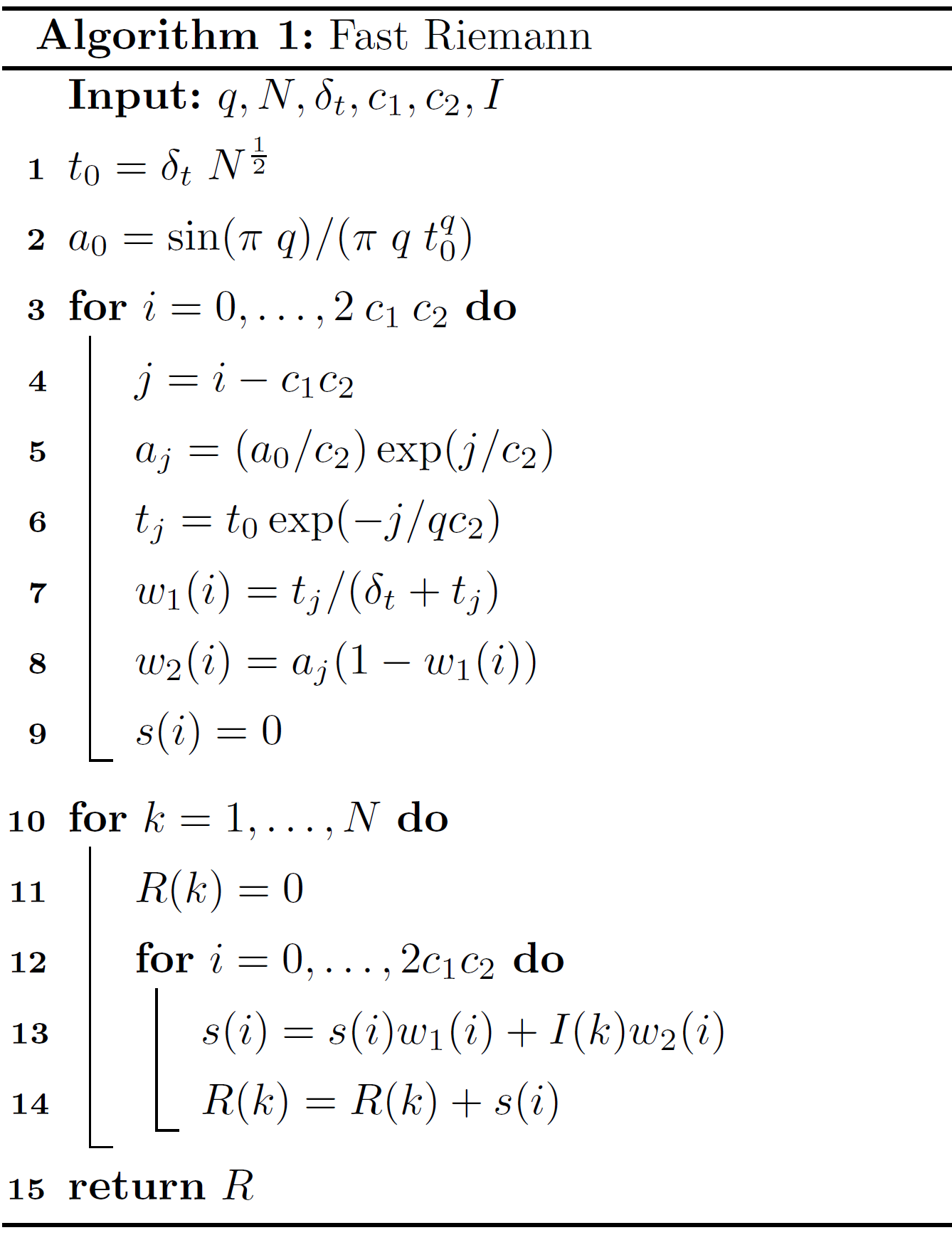
Here, \(R\) represents the calculated semi integral, i.e. \(R \approx \frac{\mathrm{d}^{v}}{\mathrm{d}t^{v}} I(t)\).
Call Algorithms
A generalized call is implemented, in which the user can define with v the operation i.e. semi integration
(v \(=-0.5\)) or semi differentiation (v \(=0.5\)) for a predefined dataset (y and t).
Furthermore he can optionally set a flag (alg) to select a specific algorithms and with
transonic_backend he apply a speed up by transonic (with numba or pythran backend).
Available algorithms (alg ):
frlt: Fast Riemann-Liouville transformation (default)
g1: Gruenwald
r1: Riemann and Liouville
Available backends (transonic_backend ):
python: Transonic package with python backend
numba: Transonic package with numba backend
pythran: Transonic package with pythran backend (default)
d_tol (by default: \(1 \cdot 10^{-5}\)) defines the maximum relational difference between individual
step and the average step size. It can be modified, if the time steps are not equally spaced.
c1, c2 (by default \(8\) and \(2\)) are the fast Riemann filter constants. They are only
used by the frlt algorithm and otherwise ignored. They trade accuracy against computation time and may
need to be increased to suppress the “inverted peak” artifacts for larger data sets (see fast_riemann).
The generalized semi_integration function can be imported and executed by:
from ec_tools.semi_integration import semi_integration
semi_integration(y, t, alg, transonic_backend)
The implemented algorithms can be selected by the alg flag (see above) or
the algorithms can be imported and executed individually for more control (see below).
Since the semi-integration can be more or less computationally intensive the possibility to speed up the computation by relying on the transonic library is included.
Gruenwald Algorithm
Implementation of the Gruenwald algorithm for
semi-integration (v \(=-0.5\)) and semi-differentiation (v:math:` =0.5`)
based on Oldham [3].
Input:
y: y-values
delta_x: step size (i.e. x2-x1)
v: \(-0.5\) (default) or in range \(-1 < v < 1\)
EXAMPLES:
Simple examples to verify the algorithm by applying semi-integration twice (i.e. resulting in a normal integration) and comparing the result with a numerical integration from scipy. First, the input data is a function with constant \(y\):
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0,1000, 1001)
>>> delta_x = x[1] - x[0]
>>> y = np.array([1]*1001)
>>> np.allclose(gruenwald(gruenwald(y,delta_x),delta_x)[:-1], cumulative_trapezoid(y,x), rtol=1e-15)
True
Second test with more application-related values from a gaussian distribution function (from scipy):
>>> from scipy.stats import norm
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0, 8, 1001)
>>> delta_x = x[1] - x[0]
>>> y = norm.pdf(x,4,1)
>>> np.allclose(gruenwald(gruenwald(y,delta_x),delta_x)[:-1], cumulative_trapezoid(y,x), rtol=1e-1)
True
Import the Gruenwald function directly by:
from ec_tools.semi_integration import gruenwald
res = gruenwald(I, delta_t, v)
Riemann Algorithm
Implementation of the Riemann algorithm for
semi-integration (v \(=-0.5\)) and semi-differentiation (v:math:` =0.5`)
based on Oldham [3].
Input:
y: y-values
delta_x: step size (i.e. x2-x1)
v: -0.5 (default) or 0.5
EXAMPLES:
Simple examples to verify the algorithm by applying semi-integration twice (i.e. resulting in a normal integration) and comparing the result with a numerical integration from scipy. First, the input data is a function with constant \(y\):
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0,1000, 1001)
>>> delta_x = x[1] - x[0]
>>> y = np.array([1]*1001)
>>> np.allclose(riemann(riemann(y,delta_x),delta_x)[:-1], cumulative_trapezoid(y,x), rtol=1e-0)
True
Second, test with more application-related values from a gaussian distribution function (from scipy):
>>> from scipy.stats import norm
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0, 8, 1001)
>>> delta_x = x[1] - x[0]
>>> y = norm.pdf(x,4,1)
>>> np.allclose(riemann(riemann(y,delta_x),delta_x)[:-1], cumulative_trapezoid(y,x), rtol=1e-0)
True
Import the Riemann function directly by:
from ec_tools.semi_integration import riemann
res = riemann(I, delta_t, v)
Fast Riemann Algorithm
Implementation of the fast Riemann algorithm for semi-integration. based on Pajkossy et al [5]. Return the semiintegral R of order \(q\) for \(y\) with the \(x\) interval \(\delta_x\) and the filter constants \(c_1\) and \(c_2\).
Input:
y: y-values
delta_x: step size (i.e. x2-x1), by default 1
v: -0.5 (default) or 1 < q < 0
c1, c2: filter constants (default c1: 8, c2: 2)
EXAMPLES: Simple examples to verfiy the algorithm by applying semi-integration twice (i.e. resulting in a normal integration) and comparing the result with a numerical integration from scipy. First, the input data is a function with constant \(y\):
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0,1000, 1001)
>>> delta_x = x[1] - x[0]
>>> y = np.array([1]*1001)
>>> np.allclose(fast_riemann(fast_riemann(y, delta_x=delta_x), delta_x=delta_x),
... cumulative_trapezoid(y,x,initial=0), rtol=2.5e-03)
True
Second, test with more application-related values from a gaussian distribution function (from scipy):
>>> from scipy.stats import norm
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0, 1000, 1001)
>>> delta_x = x[1] - x[0]
>>> y = norm.pdf(x,500,1)
>>> np.allclose(fast_riemann(fast_riemann(y, delta_x=delta_x), delta_x=delta_x),
... cumulative_trapezoid(y,x,initial=0), rtol=1e-0)
True
Increase the number of samples:
>>> x = np.linspace(0,1000, 10001)
>>> delta_x = x[1] - x[0]
>>> y = np.array([1]*10001)
>>> np.allclose(fast_riemann(fast_riemann(y, delta_x=delta_x), delta_x=delta_x),
... cumulative_trapezoid(y,x,initial=0), rtol=5e-03)
True
>>> from scipy.stats import norm
>>> from scipy.integrate import cumulative_trapezoid
>>> x = np.linspace(0,1000, 10001)
>>> delta_x = x[1] - x[0]
>>> y = norm.pdf(x,500,1)
>>> np.allclose(fast_riemann(fast_riemann(y, delta_x=delta_x), delta_x=delta_x),
... cumulative_trapezoid(y,x,initial=0), rtol=1e-0)
True
Import the Fast Riemann function directly by:
from ec_tools.semi_integration import fast_riemann
res = fast_riemann(I, delta_t, v)
Testing
In this section the semi-algorithms are tested on simple and more applied functions in order to investigate their accuracy, general functionality and performance regarding time and deviations (absolute and relative errors).
Accuracy Test
Single Semi Integration
In order to evaluate the general quality of the semi-integration algorithms, first some simple functions are considered, i.e. \(f = C\) (any constant), \(f = x\) and \(f = x^2\). Oldham provides in his literature [4], a table in chapter 7.3 (p. 118f) with
the resulting semi-differentiation (\(v=0.5\)) and semi-integration (\(v=-0.5\)) of different functions. These results are derived by specialization of the rules given in tha chapters 3-6 in [4]. The following table shows the results for the chosen cases.
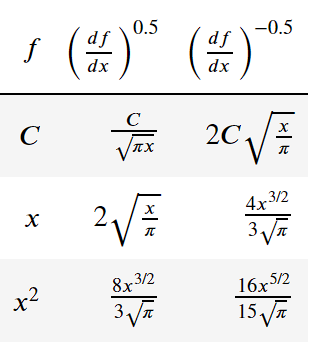
Furthermore, Oldham provides in his book [4] in chapter 8.2 a table (8.2.1), which gives the relative errors for different semi-integration algorithms. The next table provides these expected relative errors for our implemented algorithms (G1: Gruenwald; R1: Riemann). There, \(ζ\) is the Riemann zeta function, which is already implemented in scipy.special.zeta. For Riemann, the relative error applies only for semi-integration (i.e. \(q<0\)).
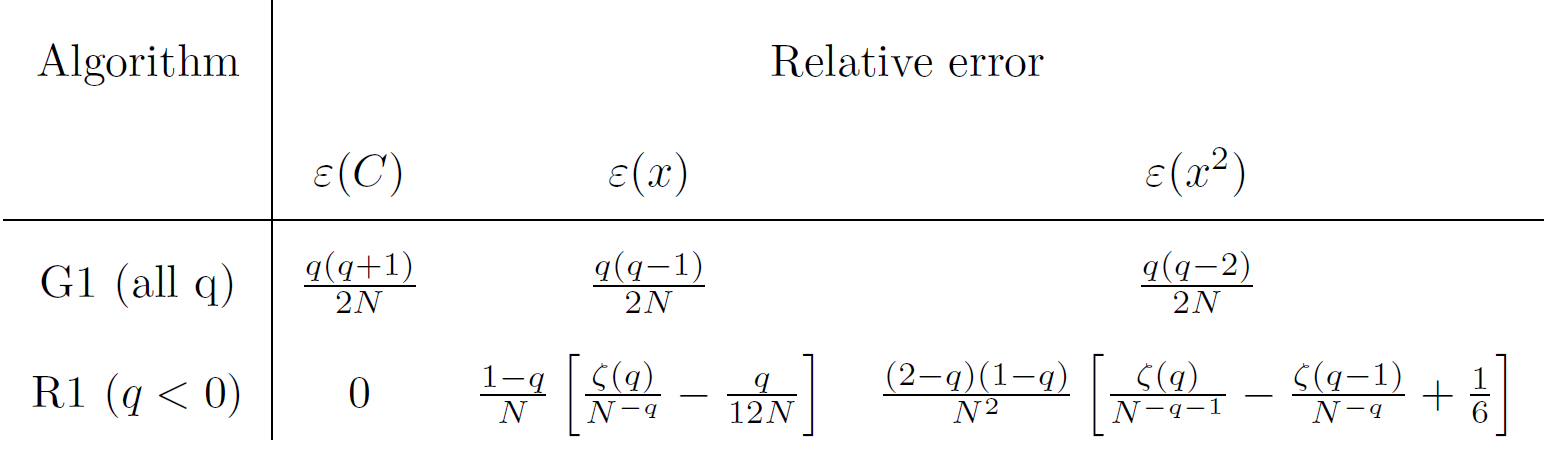
Test 1: \(f=1\) (constant)
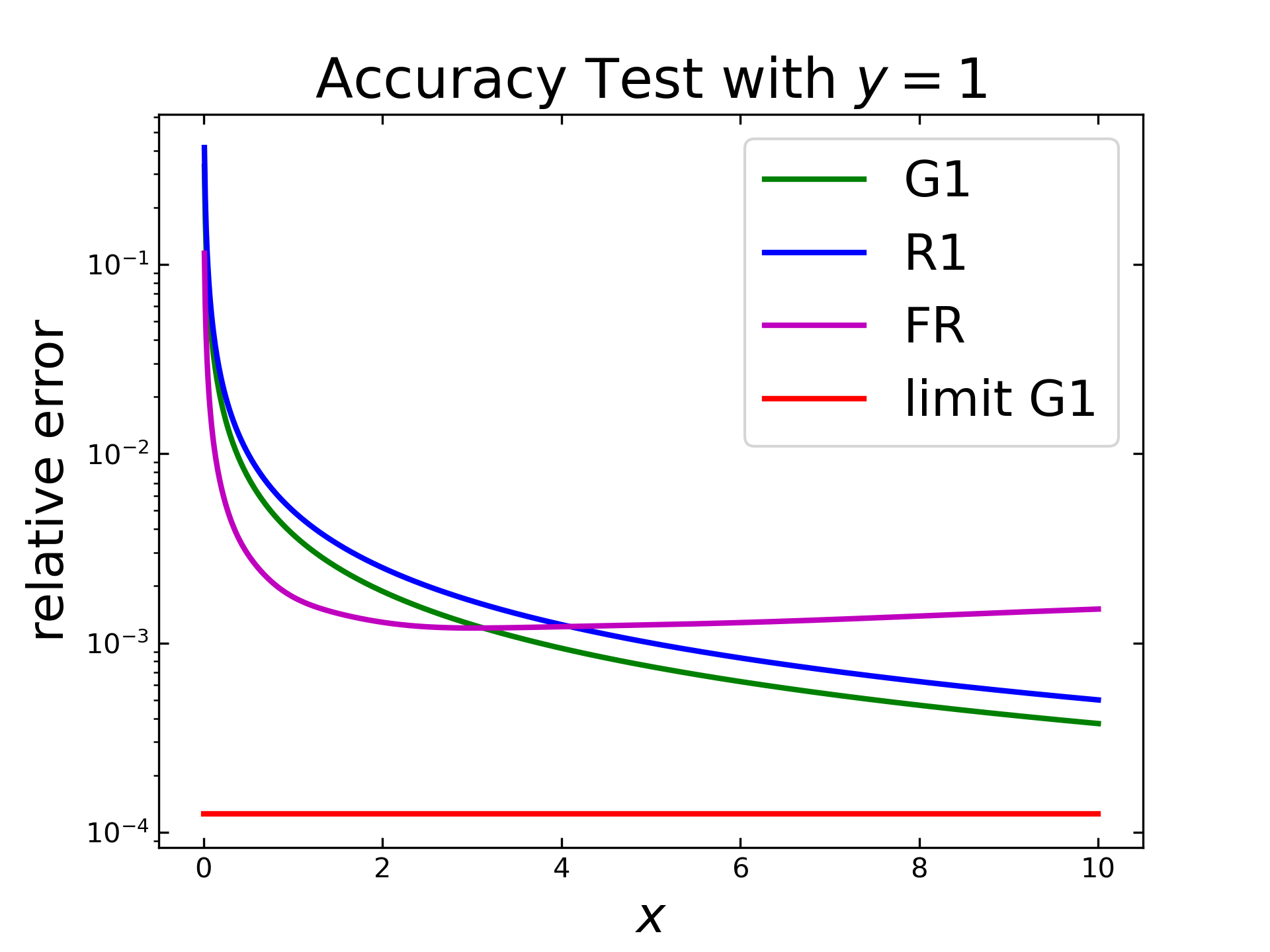
In the first test, the accuracy (relative error) of the implemented algorithms is tested with a constant function (\(f=1\)) with \(1000\) steps. The following figure shows the relative error (semi logarithmically) along an x-range. The Gruenwald algorithm (green) exhibits a declining error but does not reach the predicted lower limit (red) from Oldhams table. The Riemann algorithm (blue) shows a similiar decrease of the relative error, but does not reach its predicted limit.
The lower limit for Rieman is not displayed here, as it should be zero (i.e. exact) for this case. The purple curve displays the result of the fast Riemann, which shows first a stronger decrease but then it increases slightly.
Test 2: \(f=x\)
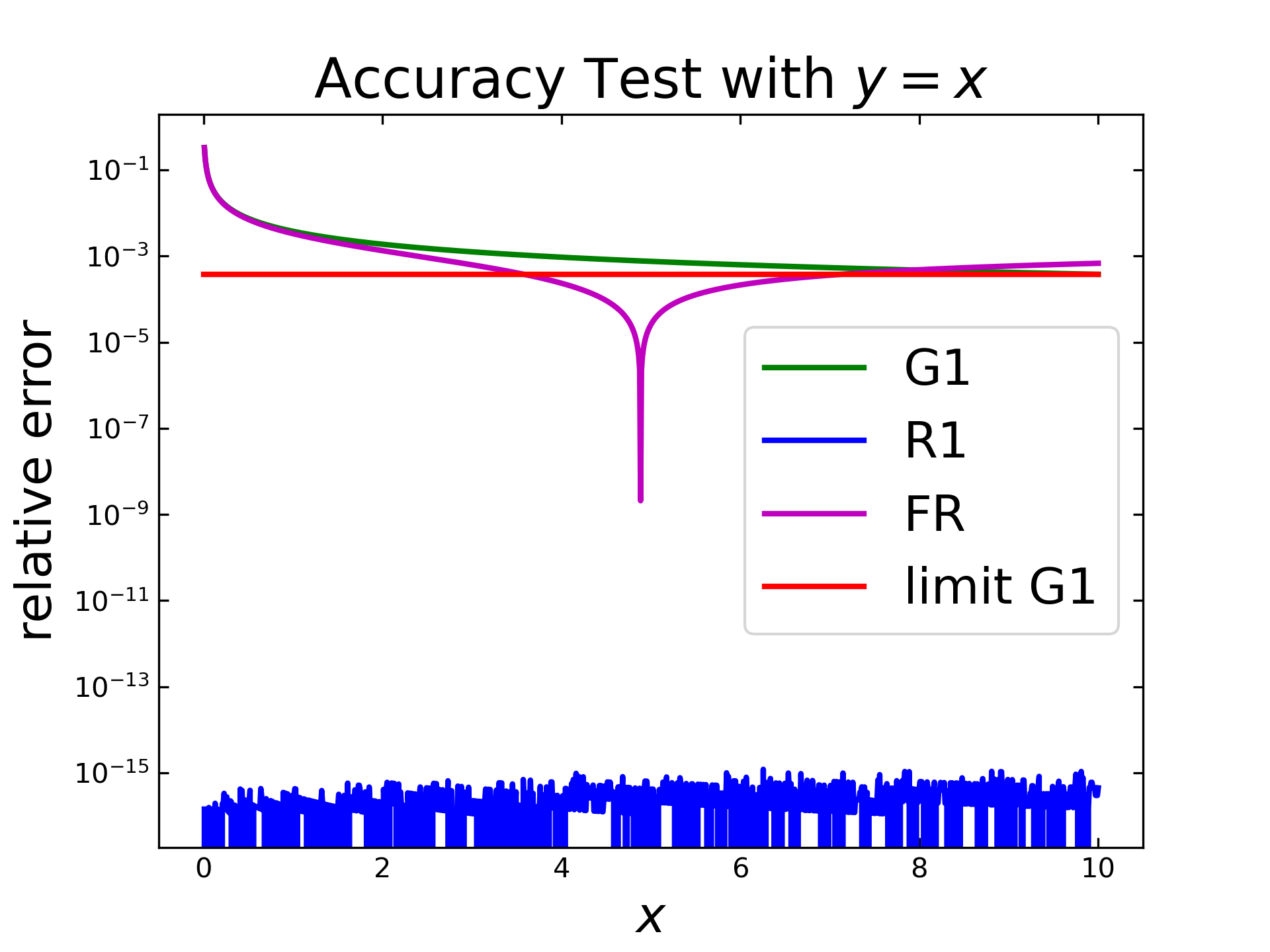
The next test covers the application on \(f=x\) with same other settings as before. The Riemann algorithm (blue) reaches in this case already the machine precision (\(\varepsilon_{f64}=2.22 \cdot 10^{-16} \)), i.e. it is as accurate as possible with f64 floats. The Gruenwald algorithm (green) reduces down to \(10^{-3}\) and seems to reach the predicted limit (red). The fast Riemann (purple) shows a strange behavior. At first the relative error decreases, drops sharply and, increases again. This so-called inverted peak will be discussed later, as the \(c\) parameters of that algorithm play an important role to that behaviour.
Test 3: \(f=x^2\)
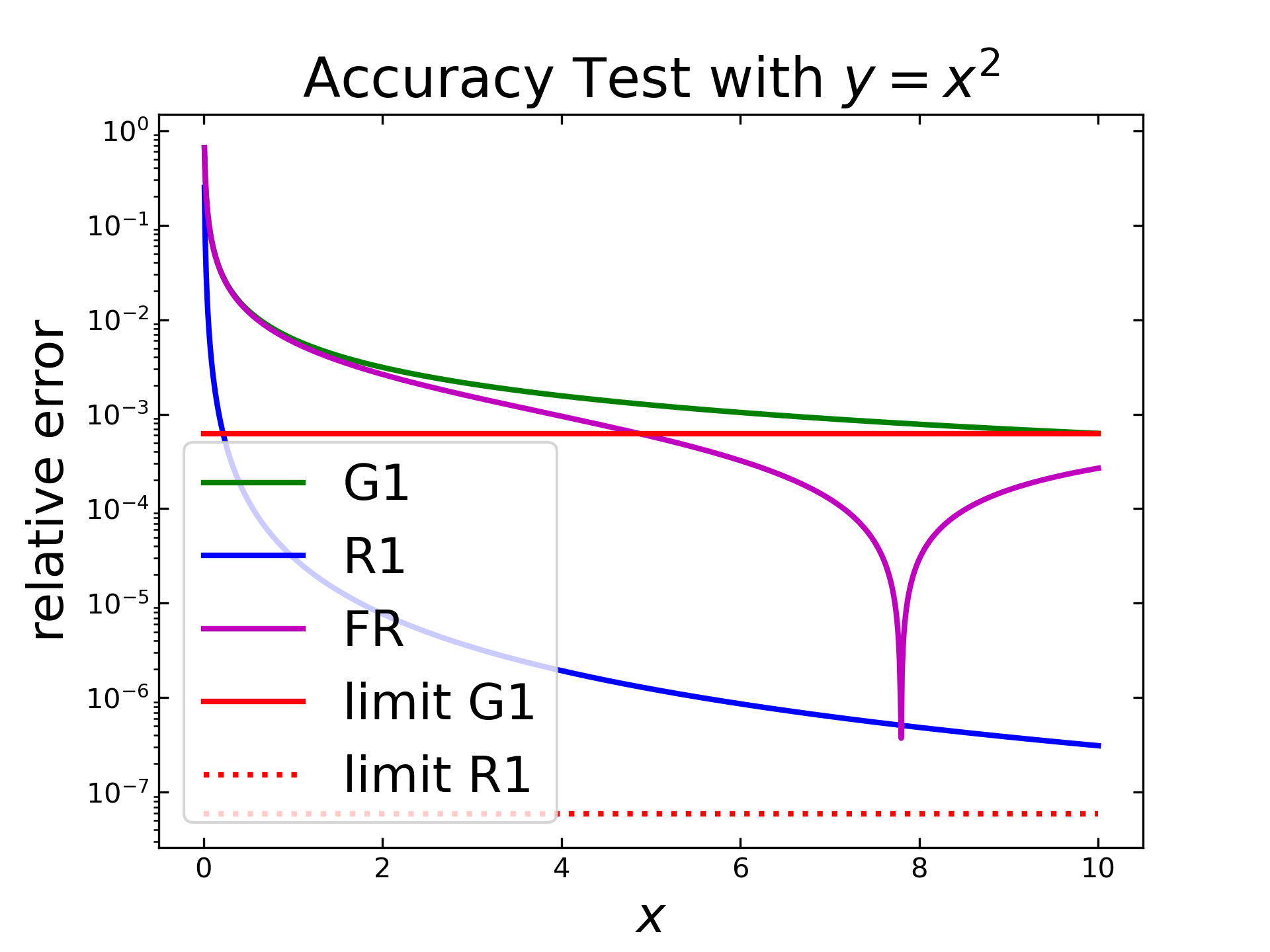
The last test with \(f=x^2\) and same other settings steps is displayed in the following figure. Here, the Gruenwald algorithm (green) behaves similar to the first case and reaches already the mentioned limitation (red). The Riemann algorithm (blue) has a stronger decrease and seems to approach its predicted limitation (red, dotted) also. The fast Riemann shows again an inverted peak, similar to the test with \(f=x\).
Full Integration
The previous Tests show, that all algorithms can perform a single semi-integration with suitable accuracy for many applications. By performing a semi-integration twice, the result should be the same as the one from a full integration with common numerical methods. Therefore, the same functions as before are used as input. The integral for all three cases is also given, as the functions are quite simple. In addition, one numerical integration method (from scipy), namely the cumulative trapezoidal one will be also applied and compared.
Test 1: \(f=1\) (constant)
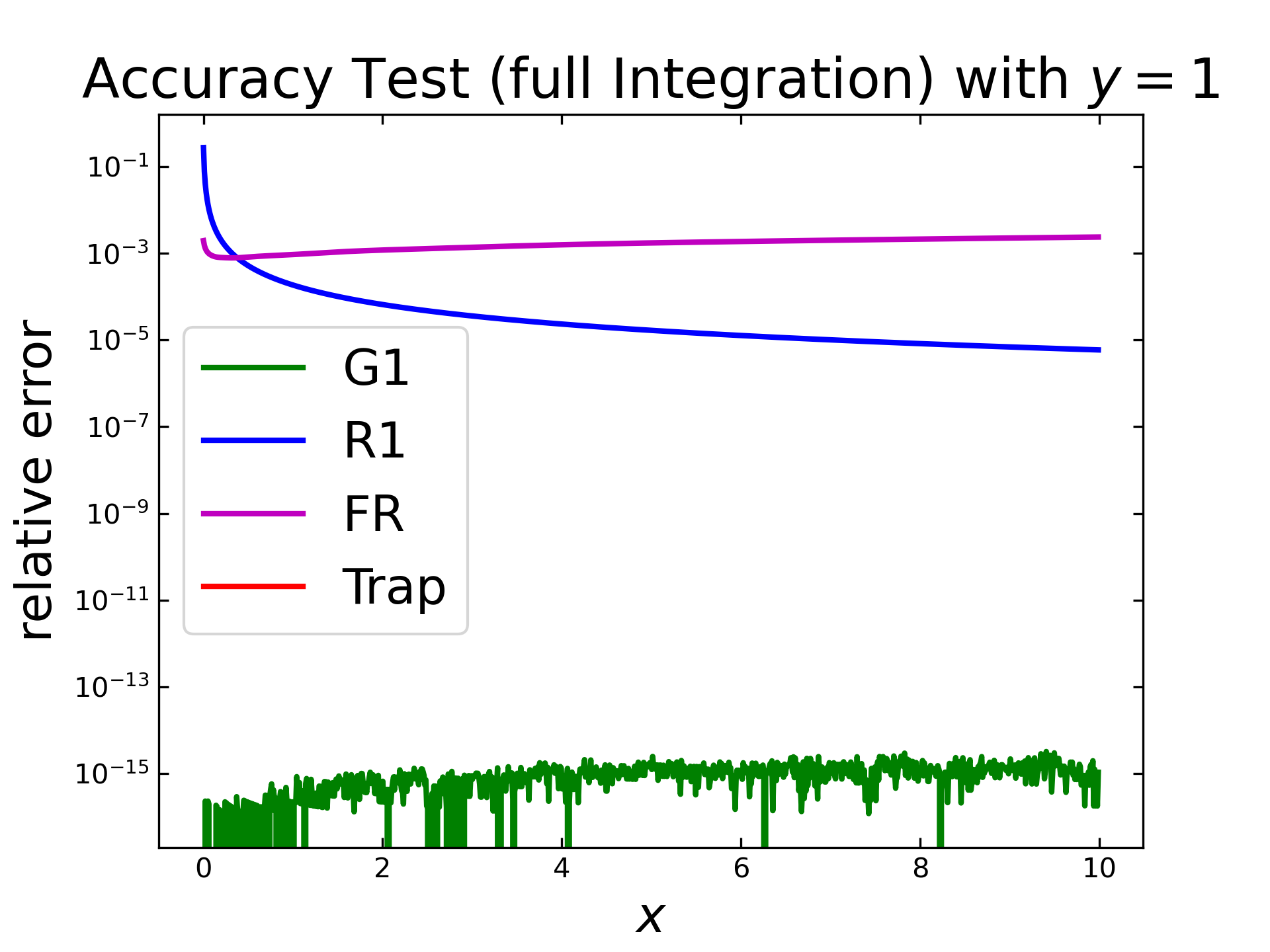
The first test case considers the constant function as input and all semi-integration methods are applied twice. The next figure shows the relative error (logarithmically) along the x values. Here the Gruenwald algorithm (green) shows results close to the machine precision. Behind that graph is also the graph for the numerical integration (red) hidden, with the same precision. The Riemann algorithm (blue) shows again a steady decease and the fast Riemann (purple) is around \(10^{-3}\) and increases slowly.
Test 2: \(f=x\)
With the case of \(f=x\), the implemented semi-integration algorithms show nearly the same decrease, except that for fast Riemann (purple) where the inverted peak is visible again. The numerical integration (red) is here close to machine precision, again.
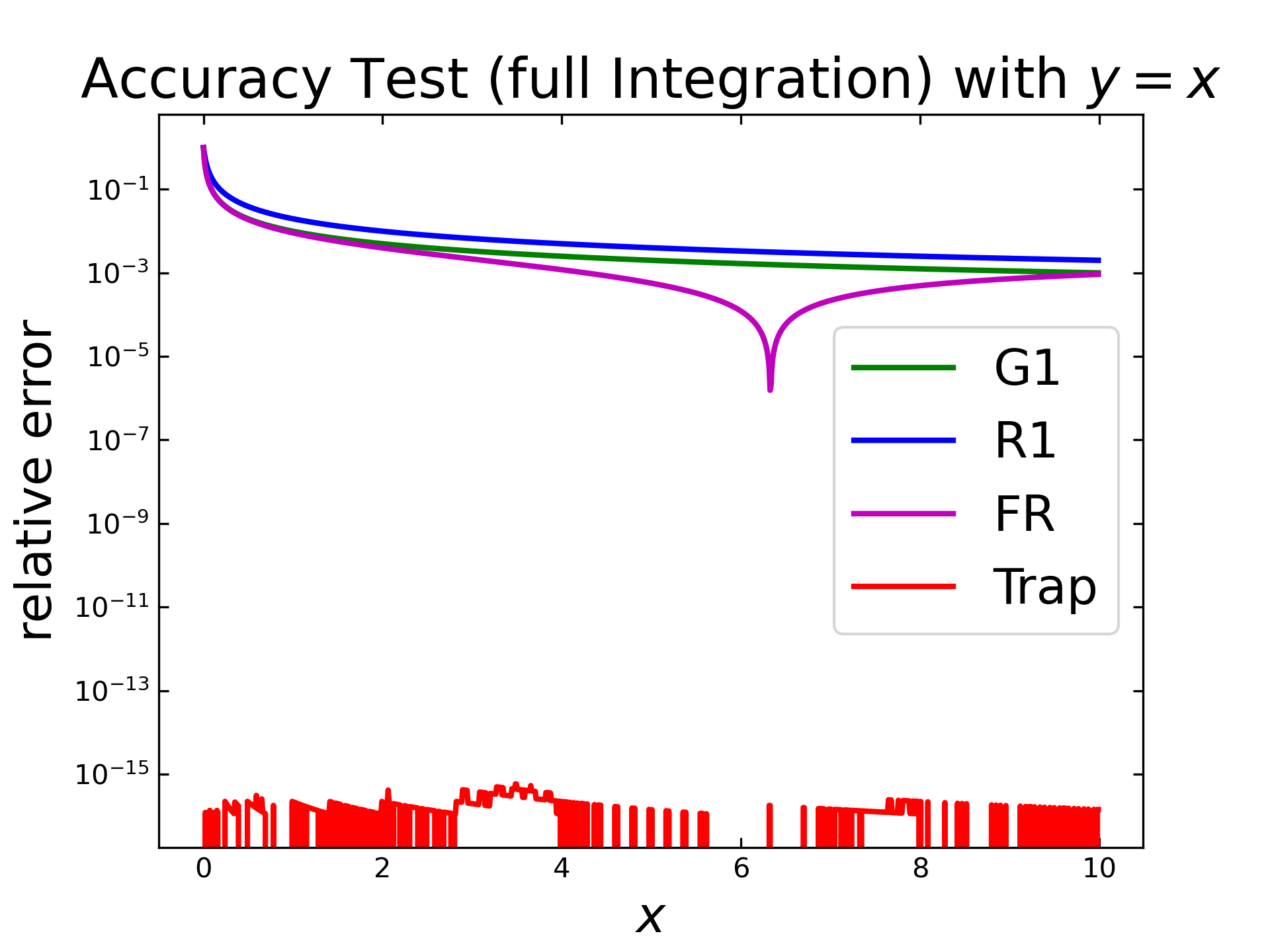
Test 3: \(f=x^2\)
The last test case with \(f=x^2\) shows similar results like previous. All three implemented semi-integration algorithms are quite similar, except the inverted peak for fast Riemann (purple) and the numerical integration (red) with an relative error, down to less then \(10^{-6}\).
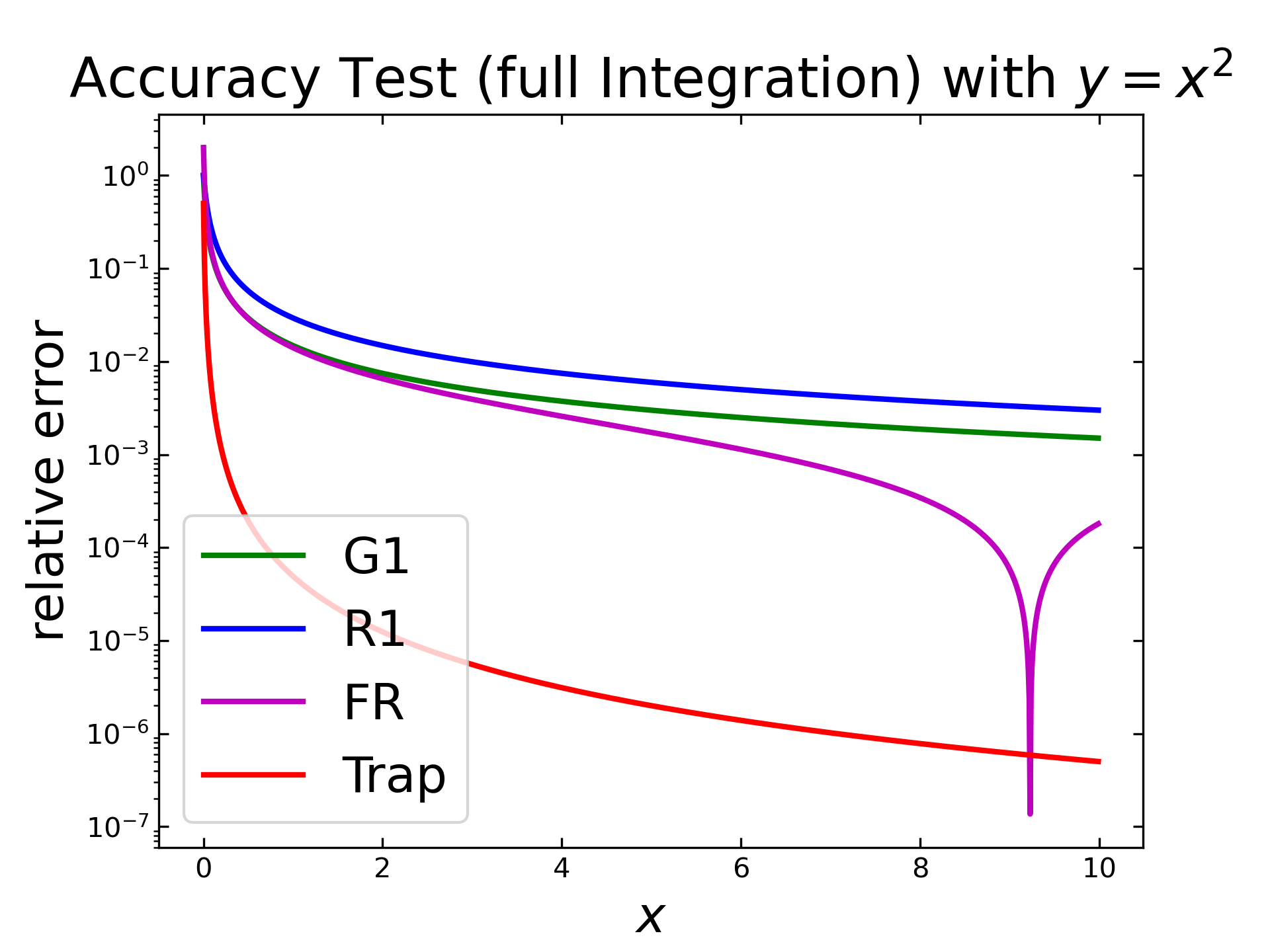
Full Integration with Realistic Values
The previous tests only consider the accuracy of simple functions. In order to investigate the accuracy at more realistic functions, a gaussian distribution function (by scipy.stats) will be used as input. To evaluate the relative error, the implemented algorithms are applied twice (i.e. ‘full’ integration) and are compared with the results of a numerical integration (by scipy.integrate).
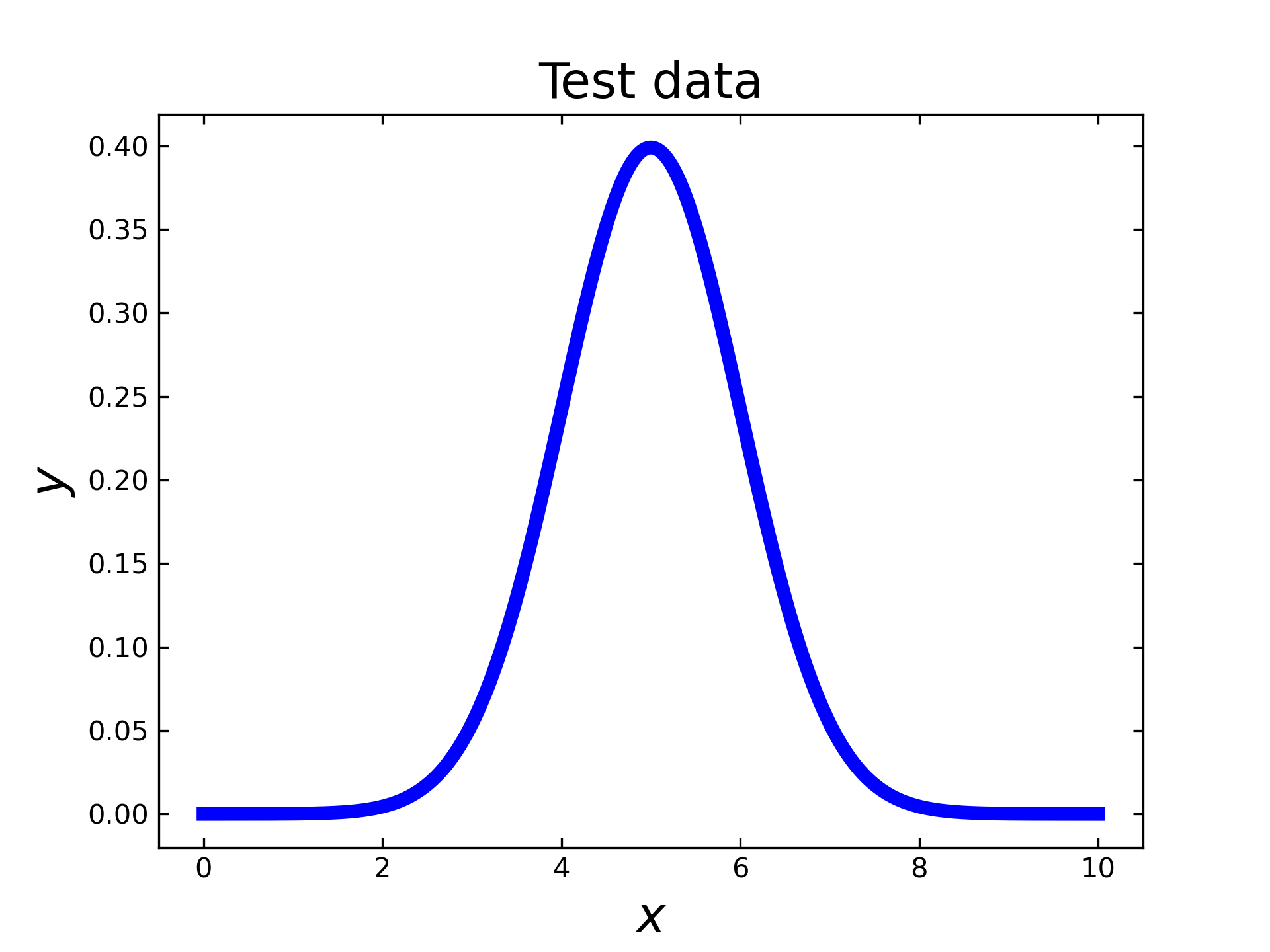
Since this case is more realistic than the previous one, the used code is given here step-by-step. First, all necessary packages need to be imported (i.e. numpy, scipy stats and scipy integrate). Afterwards, the x- & y-vales are generated. As the step size is constant, delta can be calculated by the very first values. The resulting test function is displayed below the code.
import numpy as np
import scipy.stats import norm
from ec_tools import semi_integration as si
from scipy.integrate import cumulative_trapezoid
x = np.linspace(0,10, 1001)
y = norm.pdf(x,5,1)
delta_x = x[1]-x[0]
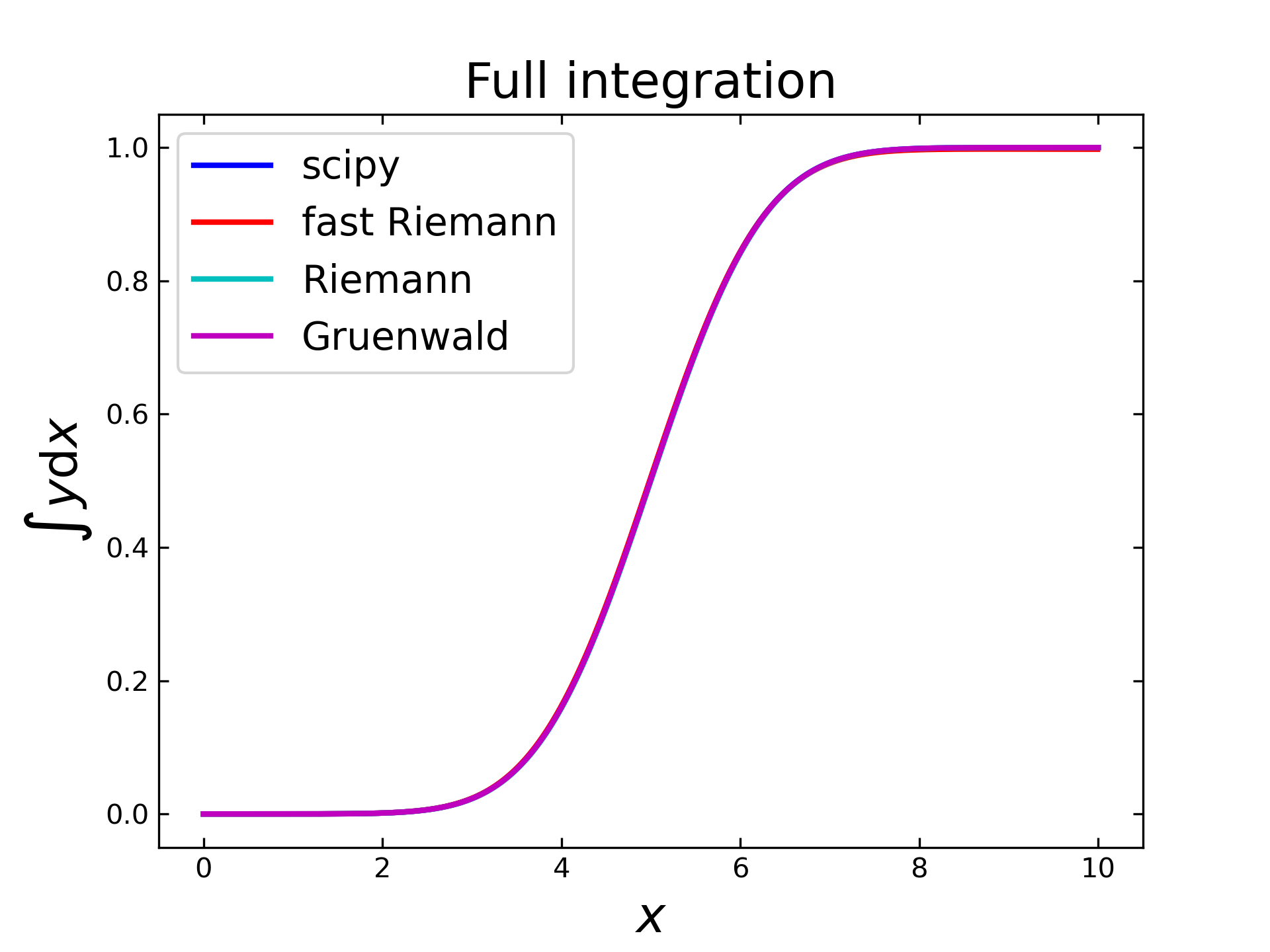
Now, the reference values are computed by the cumulative trapezoid method from scipy (numerical integration), like displayed below. In order to perform a ‘full’ integration (i.e. \(v=-1\)) with the semi integration methods, each algorithm needs to be applied twice with \(v_1=v_2=-0.5\).
d_ref = cumulative_trapezoid(y, x)
d1 = si.fast_riemann(si.fast_riemann(y, delta_x), delta_x)[1:]
d2 = si.riemann(si.riemann(y, delta_x), delta_x)
d3 = si.gruenwald(si.gruenwald(y, delta_x), delta_x)
These computed integrals (by scipy and by the implemented algorithms) are displayed below and show a wave-like function, as expected from the exemplary image in the fundamental section. Here it seems, that all graphs are nearly overlapping. To determine the real differences, the absolute and the relative errors have to be considered.
The following figure shows the absolute error for each algorithm in a semilogarithmic plot along the \(x\)-values. It can be seen, that the absolute error increases for each algorithm up to \(x=5\) and then decreases, except for the fast Riemann algorithm (red), which shows an sharp dip and a subsequent increase.
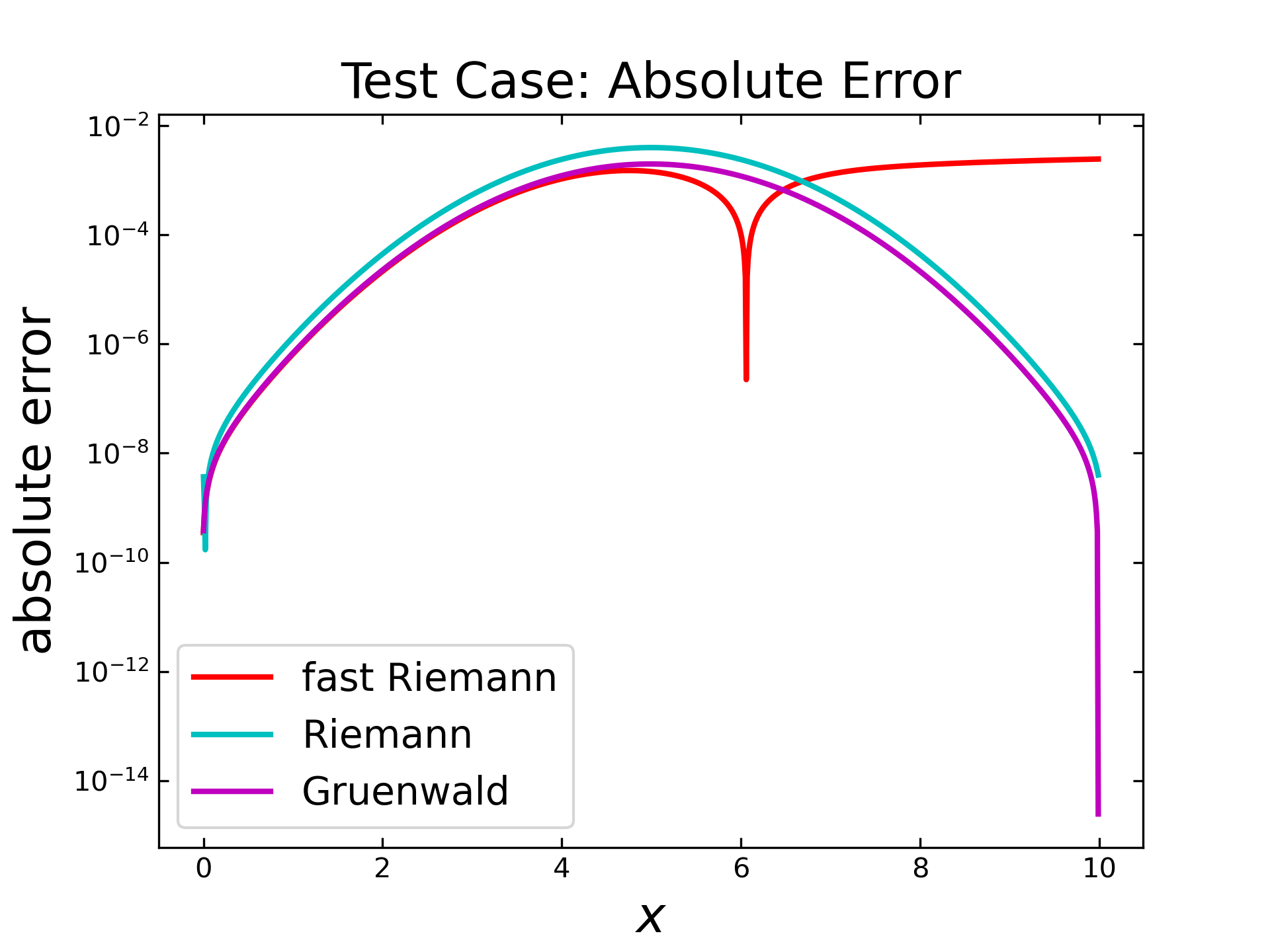
The relative error is displayed in the figure below. Here, the Riemann algorithm (cyan) has a relative high error in the very first steps and then behaves similar like the Gruenwald (magenta) algorithm by slowly decreasing and dropping at the end. The fast Riemann shows at first also a slow decrease, but then the inverted peak is again visible. This behavior is caused by the predefined \(c\) parameters of that algorithm (like mentioned previously) and will be examined separately in a subsequent section.
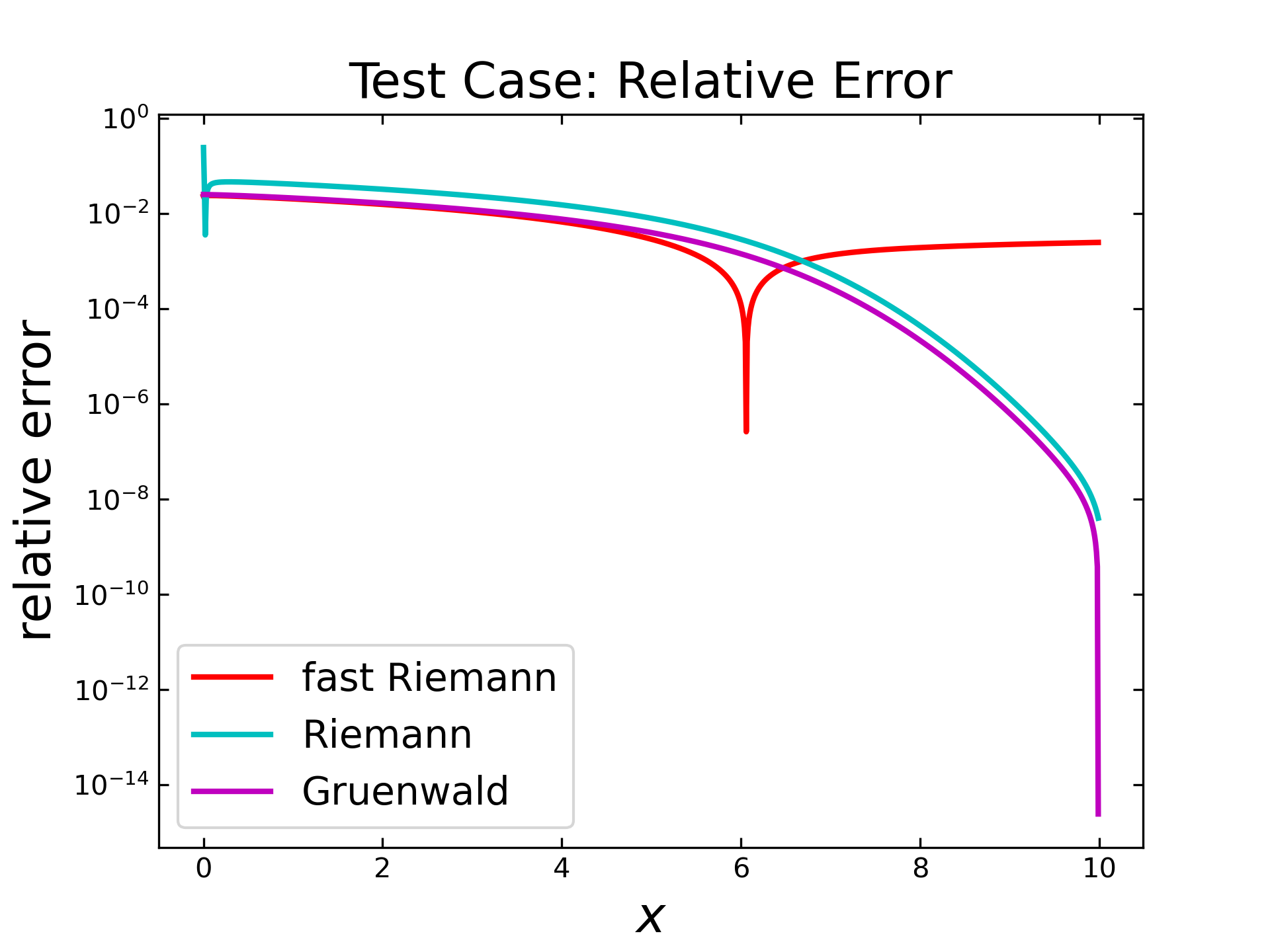
The accuracy of these algorithms is more or less sufficient, depending on the relatively low number of steps. In order to consider larger sets, the similar setup is applied for \(10000\) steps. Therefore, the next figure shows the resulting absolute error for each algorithm. Here, the error of fast Riemann (red) seems to by lower at the beginning and increase similarly, like in the case with \(1000\) steps. Interestingly, the inverted peak is also visible, but this time shifted more to the left side. The Riemann (cyan) and the Gruenwald (magenta) also behave similarly to the previous test, but with lower errors.
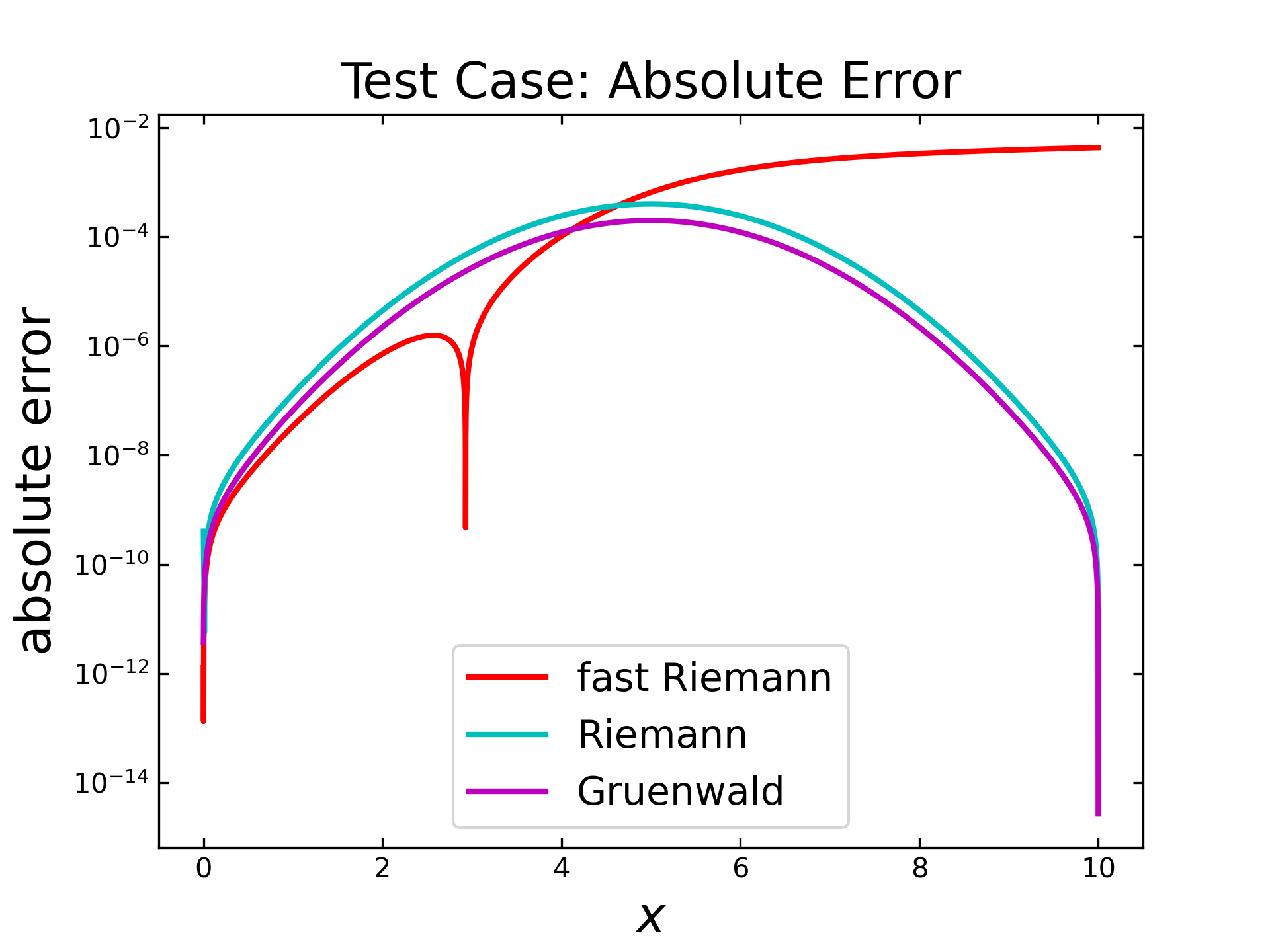
The relative errors (next figure) for all algorithms seem to behave similar, compared to results with \(1000\) steps. Only the overall error is shifted down to around one order and for fast Riemann (red) is the inverted peak visible on the left side.
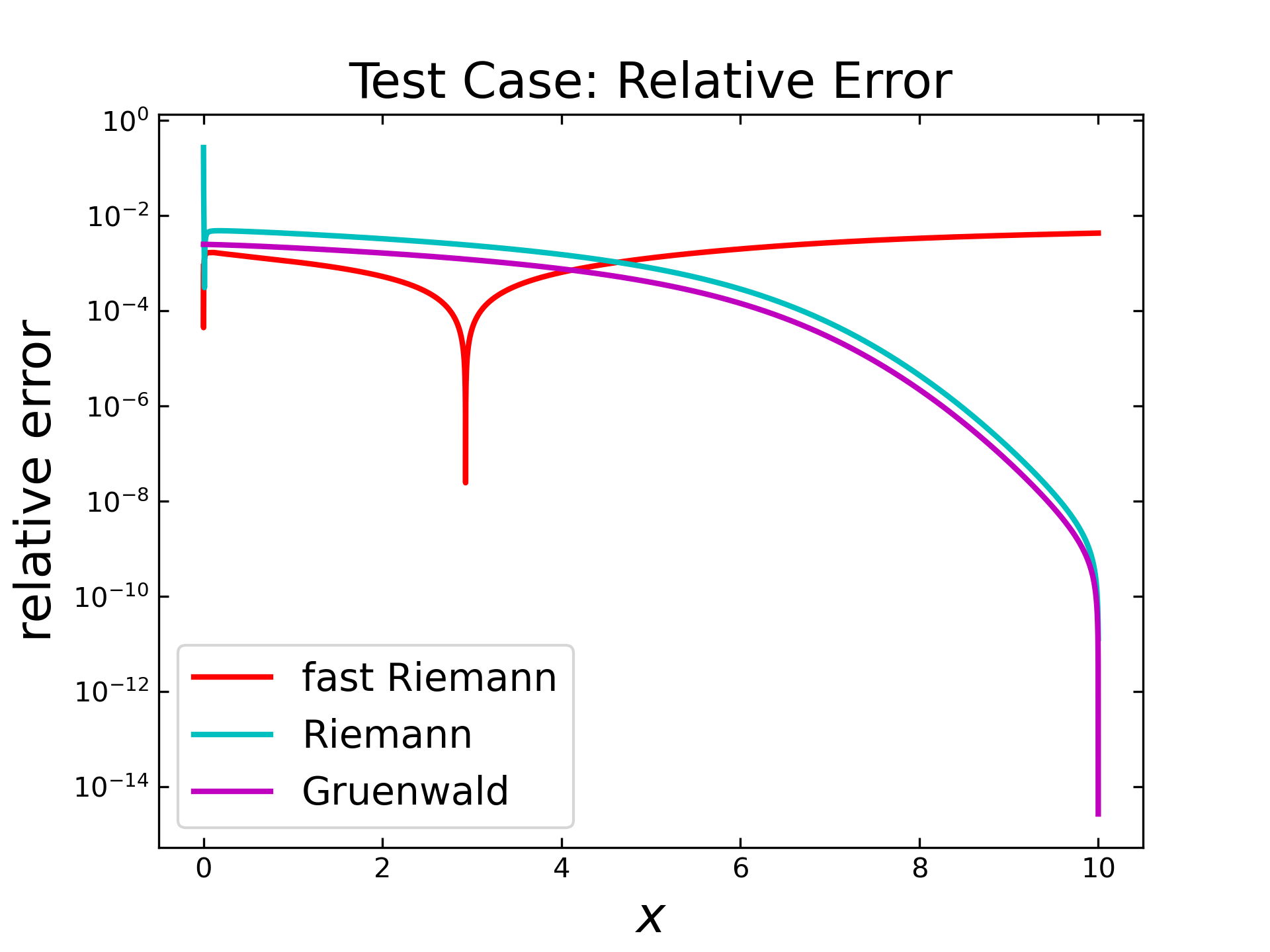
The previous tests show, that the implemented Gruenwald algorithm provides the best results, regarding the accuracy with a maximum relative error of around 1e-02. The Riemann algorithm behaves similar, but unfortunately it has a high relative error in the very first steps. The relative error of the fast Riemann algorithm is in the same range, compared to the other algorithms, except the existence of an dip and a slightly error grow, regarding higher x-values. These tests only cover the accuracy regarding the absolute and relative error. Further tests need to be done, in order to see the full possibilities of each implemented algorithm.
Functionality Test
In the previous part, the algorithms where tested by using the semi integration (\(v= - 0.5\)). In general, the algorithms could also be used for other values of \(v\). The possible application of different v values depends on the type of implementation of the different algorithms. The Gruenwald algorithm for example are implemented in such a way that theoretically all values for v are possible. In sense of integration and differentiation, it only makes sense to limit \(v\) to a range of \(-1 < v < 1\). The Riemann algorithm is more limited since the first divisor cannot be generalized, i.e. the possible settings are 0.5 and -0.5. For the fast Riemann Pajkossy set the applicable limit for \(v\) (or \(q\)) in [5] to \(-1 < q < 0\).
Semi Integration Parameter Test
The first test considers only the possible semi integrations, i.e. \(v < 0\). Therefore, \(v\) will be varied from -0.9 up to -0.1. The gaussian distribution will be used again as input, the ‘full’ numerical integration as reference and all algorithms were performed with 2000 steps. The following figure displays the computed semi integrals with the Gruenwald (G, green on left side) and the fast Riemann (FR, blue on right side) algorithm.
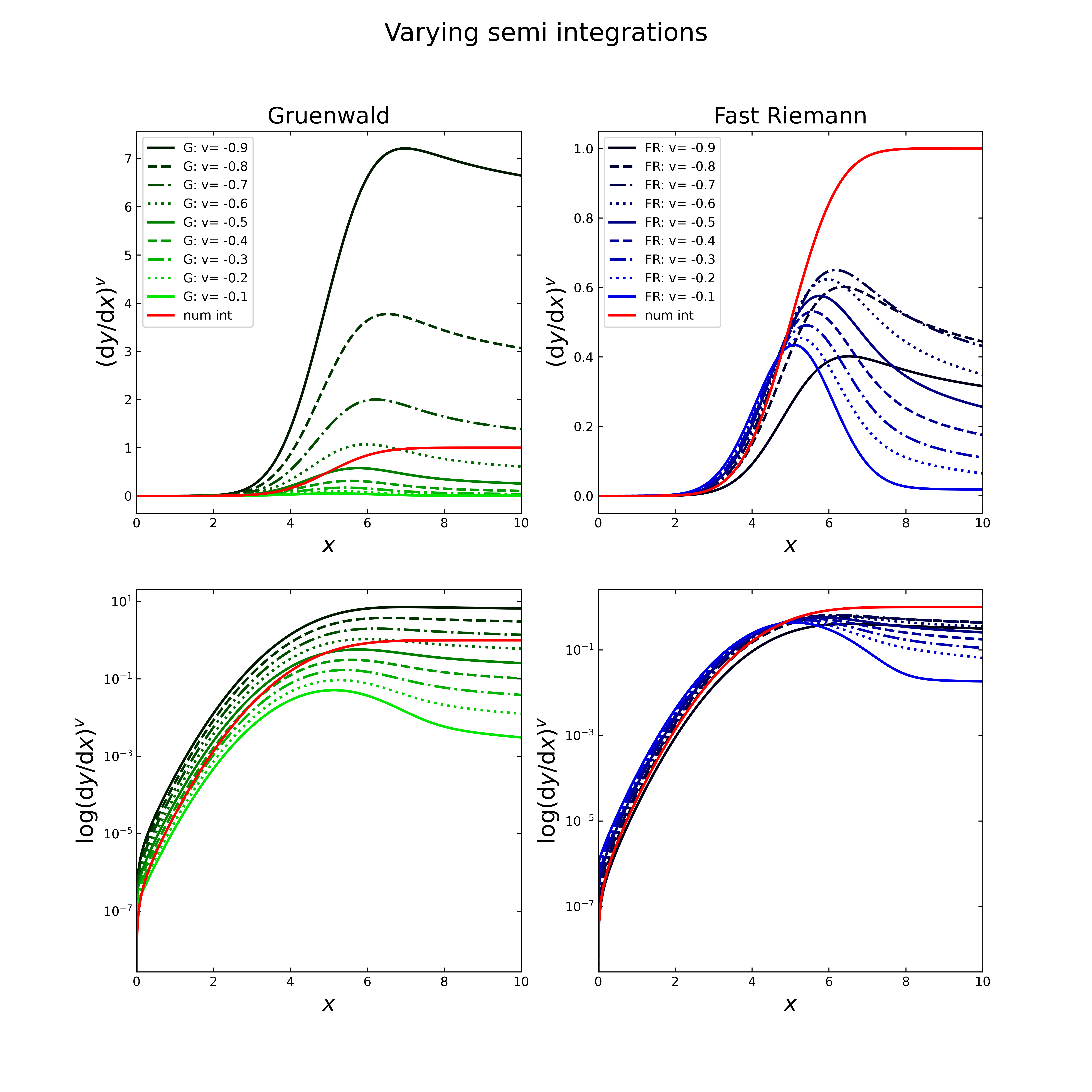
The figure above is separated in four plots. The first (top, left) shows the applied Gruenwald algorithm (green) with varying v and the “full” numerical integral (red) as reference. On the right top side are the resulting semi integrals for the implemented fast Riemann (blue). The plots below show the same results, only in semi logarithmic view.
Both algorithms allow to perform these kinds of semi integration, but the results are not comparable to each other, as the Gruenwald semi integrals are lower than the semi integrals from fast Riemann, except of course for v=-0.5. For both algorithms, the application with different v need to be used carefully, as the results cannot be validated, only v=-0.5 could be verified with the reference table from Oldham and the “full” numerical integral.
Semi Differentiation Test
The Gruenwald and the Riemann algorithm allow also a semi differentiation, i.e. \(v=0.5\). Fast Riemann has to be excluded due to the limitations stated in [5]. For the test, a fixed step size of 2000 and for the input values the computed result from the accuracy test are used, i.e. numerical integration of the gaussian distribution. With that, the ‘full’ differentiation should result in the gaussian distribution again. Therefore, the deviation between the gaussian distribution and the computed “double” semi differentiation are used to calculate the absolute error.
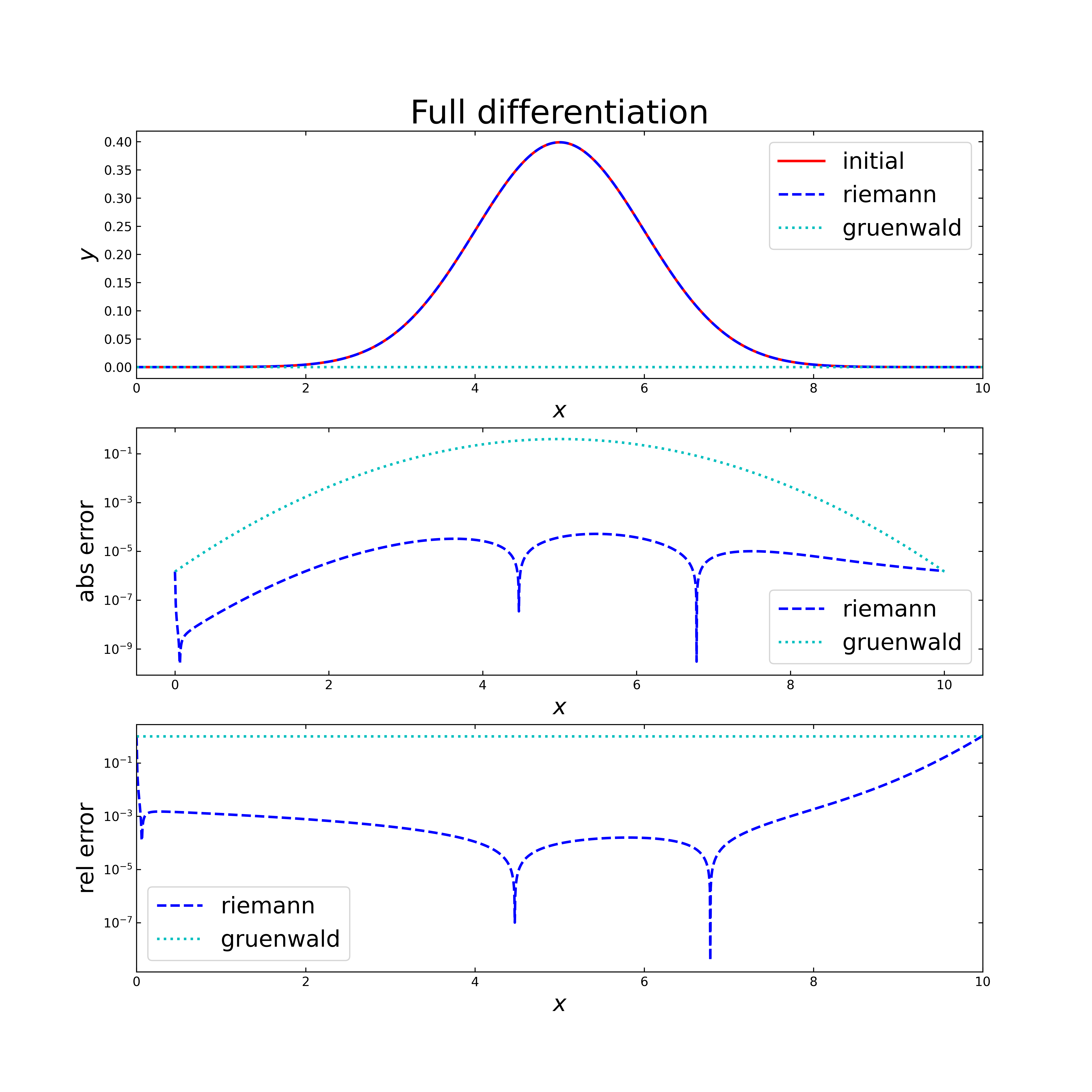
The image above shows three plots. The first (top) displays the gaussian distribution (red) as reference result (“full” differentiation from the wave-like function) and the computed differentiations by applying the semi differentiation (\(v=0.5\)) twice with Riemann (blue) or twice with Gruenwald (cyan). It is obvious, that the Gruenwald differs strongly from the gaussian distribution (initial graph), while the Riemann graph seems to overlay on the initial graph. The next semi logarithmic plot (middle) contains the absolute error of both algorithms. Here, the error of Gruenwald is high over the whole range, while the absolute error of Riemann shows quite good results with a maximum of about \(3.7 \cdot 10^{-5}\). In the last semi logarithmic plot (bottom), the relative error is shown, which has similar results. Gruenwald is out of range and Riemann shows still good results, only in the very first steps, the relative error is similar to its behavior like with the semi integrations.
It is evident, that the Gruenwald algorithm is not applicable for semi differentiations, but still useful for the application of semi integrations. In contrast to that allows the Riemann algorithm quite good results for both applications, the semi integration and differentiation, under consideration of the deviations in the very first steps. Although the fast riemann cannot be applied for semi differentiations and does not have the best accuracy, it shows a big advantage in its significantly faster calculation, compared to the other algorithms. Therefore, a performance test should show what time savings are possible.
Parameter Test for FR-Algorithm
In the description of the fast Riemann algorithm from the fundamental section, the necessity of two parameters (C1, C2) was mentioned. These parameters have a direct influence on the accuracy and the resulting computation time. If the user does not define them, they are set by default to C1=8 and C2=2, as Pajkossy proposed in [5]. This setting was the result of an accuracy test in his paper by varying parameters, applied on a simulated cyclic voltammogram with 256 and 512 steps. The previous test shows, that the algorithm could be applied for more than 10 thousand steps. Therefore, it is necessary to check the influence of a parameter variation to the accuracy. Analogous to the first accuracy test, the functions \(f=c\) (constant), \(x\) and \(x^2\) are used, including the respective semi-integration results.
Case 1: \(f=1\) (constant)
Starting with \(x=0, ..., 10\) and \(f=1\), the following figure shows on top the function (\(y=1\)) and below a semi logarithmic plot with the relative error for \(1000\) steps. Thereby, both parameters, \(C_1\)and \(C_2\) varies from \(1, 5, 10, 50\) to \(100\). Here the graph color change slowly from dark blue to bright green with increasing parameters.
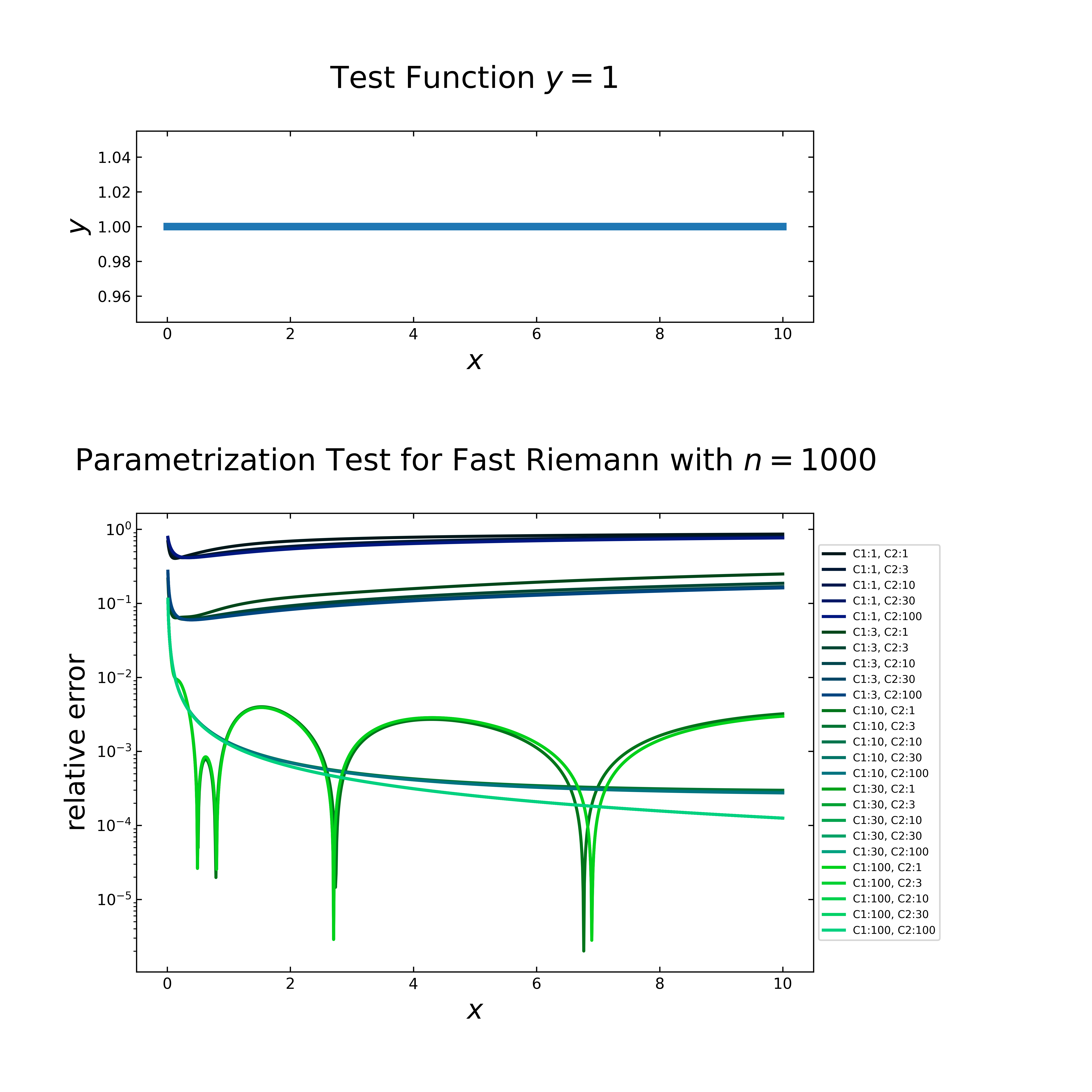
It seems, that the relative error decreases with increasing number, but at the lowest error, two graphs show multiple of the inverted peaks, like is was observed in the first accuracy test. It must also be noted, that the computation time increases also with increasing parameters, which can be seen in detail in the double logarithmic plot below. For \(C_1,C_2\) with \(1,1\) setting it requires about \(2\) ms and for \(100,100\), it needs up to \(10\) seconds. The default setting (\(8,2\)) is comparatively fast with \(17\) ms and does not contain any inverted peaks.
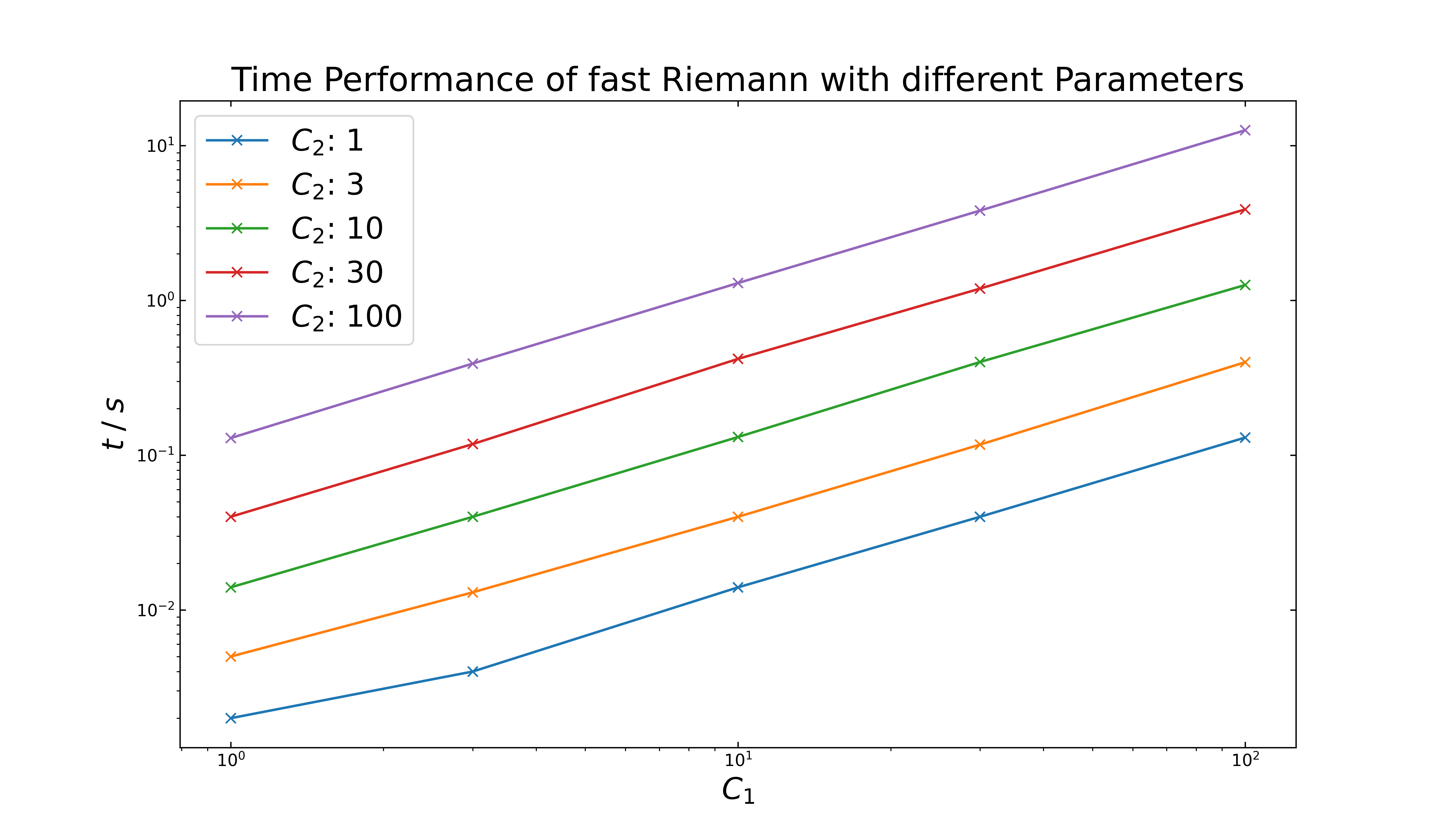
Case 2: \(f=x\)
In the next case with \(f=x\) and the same setup like in case 1, the figure below shows on top the function (\(y=x\)) and below the relative error in a semi logarithmic plot. Here arise the inverted peaks already with lower \(C_1\) values (and a variety of \(C_2\) values), while for higher \(C_1\) values, the inverted peaks decrease.
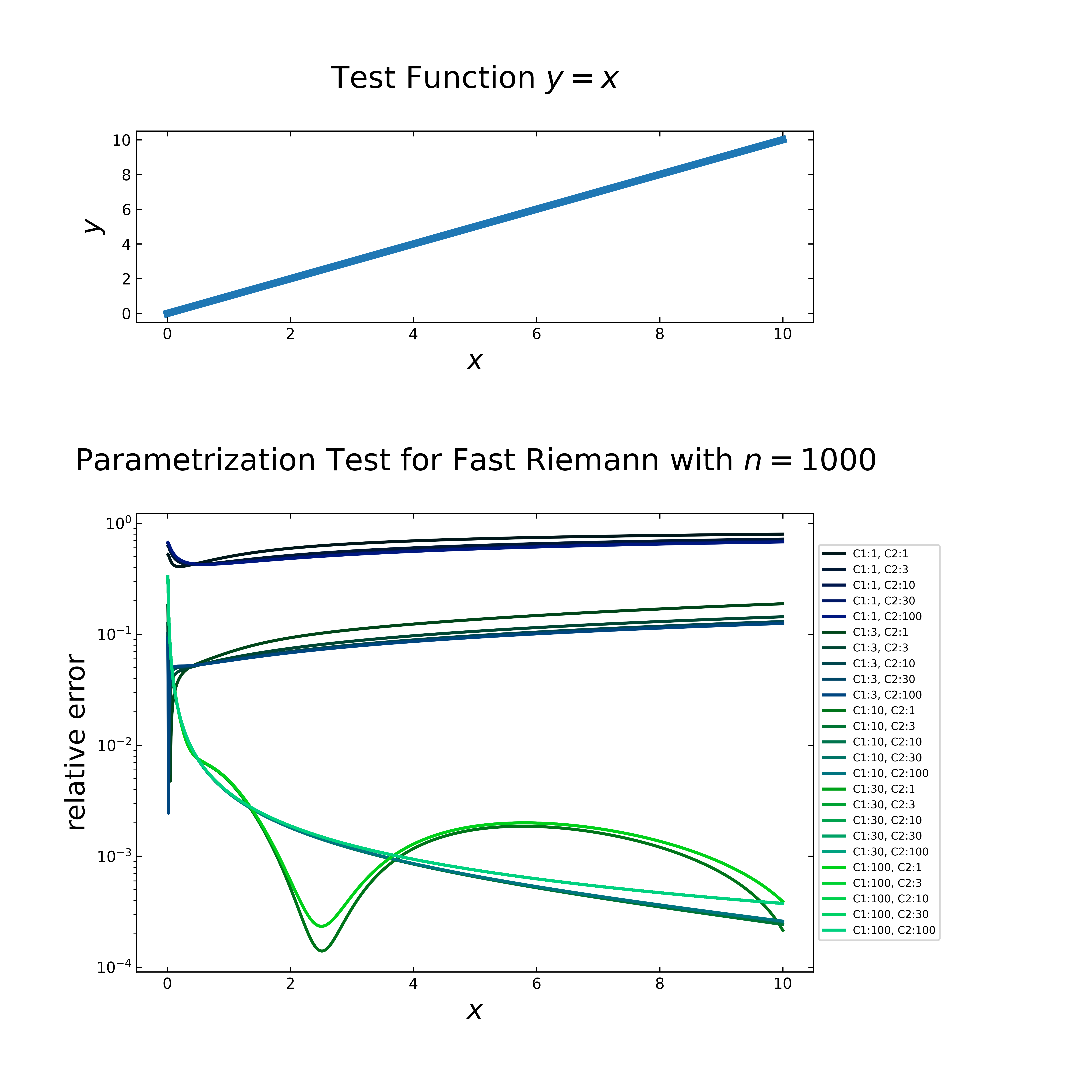
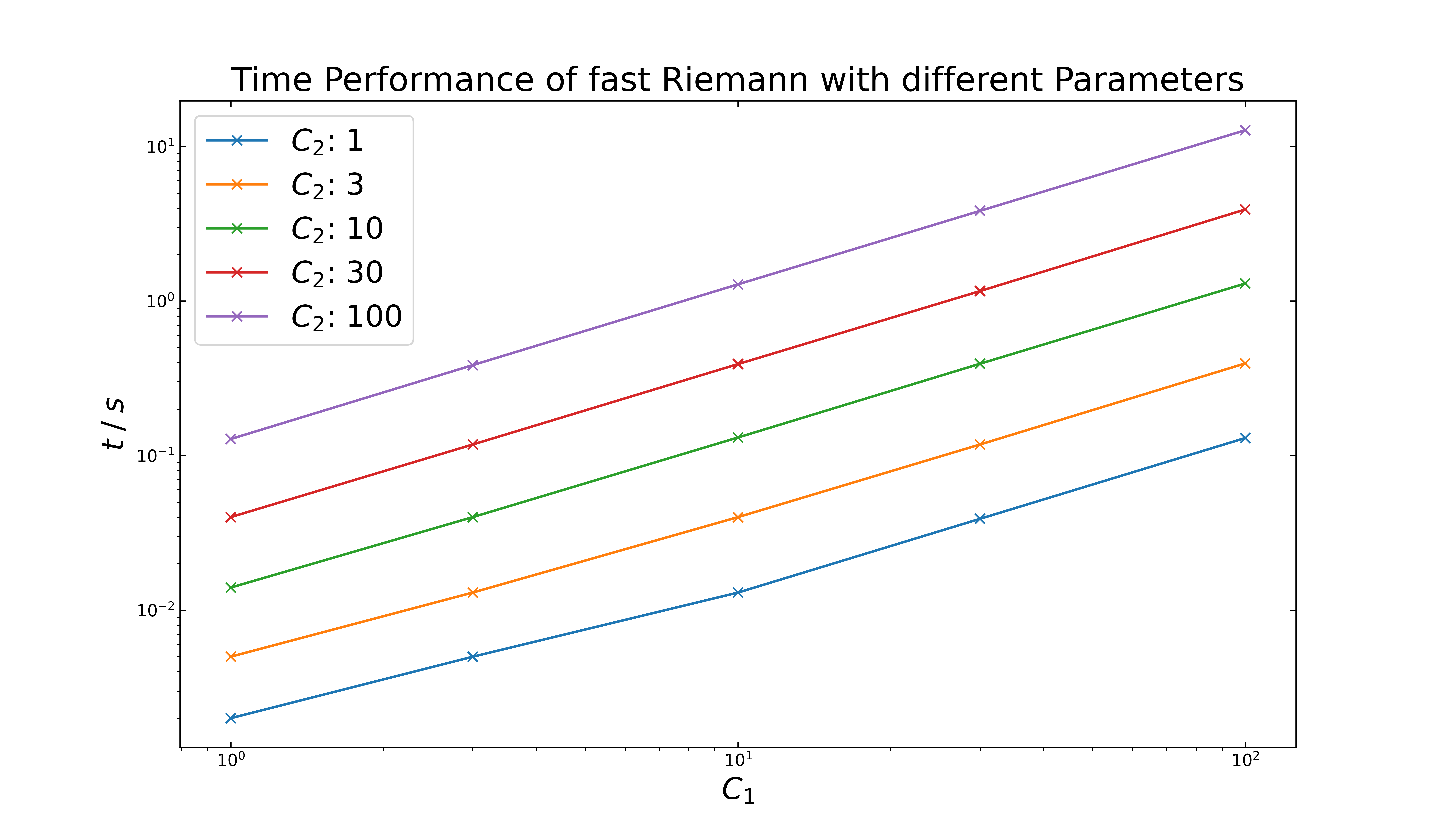
Regarding the time performance (see next figure), it is nearly equal to the first case. The default setting (\(8,2\)) is still comparatively fast with \(18\) ms, but shows an inverted peak. A step by step approach shows, that the peak disappears at \(C_1:9\) & \(C_2:4\), which results in a computation time of \(38\) ms.
Case 3: \(f=x^2\)
The last case with \(f=x^2\) (next figure, top) produces relative errors (next figure, below), which behaves quite similar to the previous case, i.e. the parameters have a strong influence to the quality of the computed values for all cases. In the case of higher \(C_1\) values, the graphs seem even to flatten the inverted peak more.
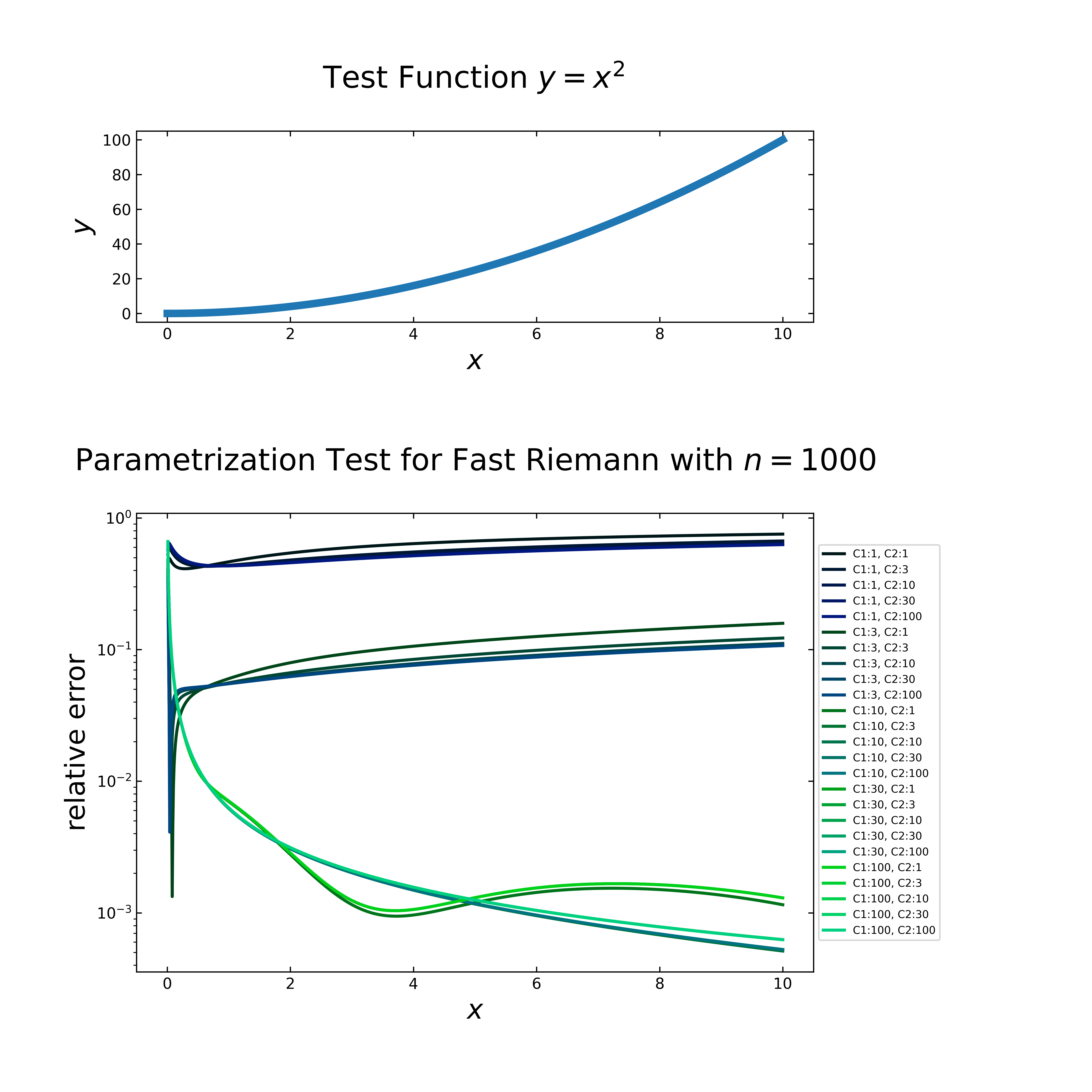
The time performance (next figure) is still comparable to the previous cases. Similar to the second case, the default values are not sufficient to achieve a stable run without one or more inverted peaks. The setting with \(C_1:9\) & \(C_2:2\) fulfills this requirement and requires \(20\) ms.
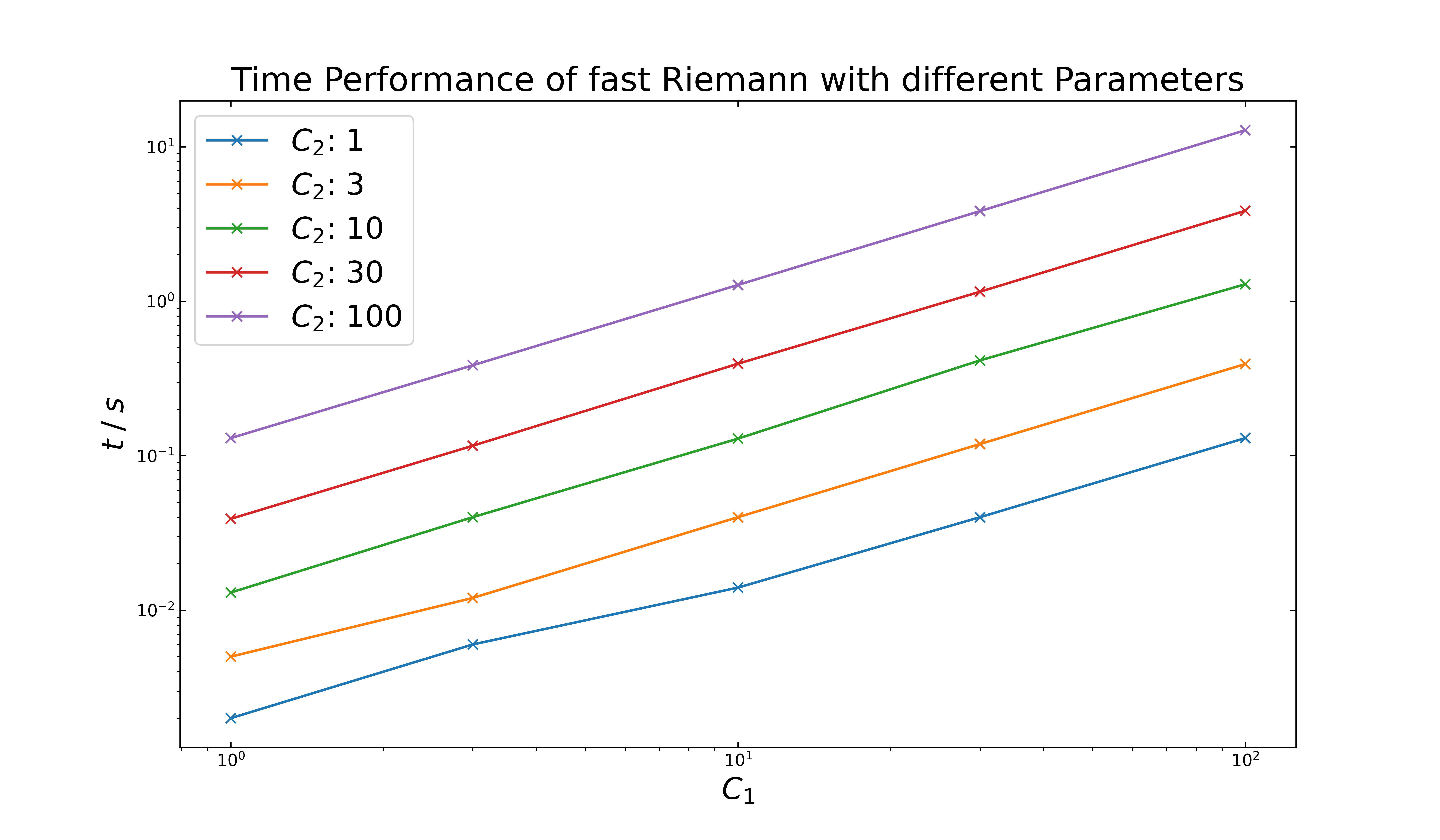
The increase of the number of steps in the above examples leads to a left-shift of already existing inverted peaks, with the same C parameters. In addition, new peaks can form at higher \(C\) values. For \(10\) thousand steps, the setting of \(C_1:13\) & \(C_2:9\) result with no formation of peaks, but it takes on average \(1.2\) seconds. For the further testing, the default values (\(C1:8, C2:2\)) are maintained.
Composition Test
The implemented algorithms are tested and compared with the results of one semi integral (\(v=-0.5\)) and the ones from numerical integration (i.e. ‘full’ integration: \(v=-1\)). In the latter case, we have taken the composition rule as given. For a ‘full’ integration or differentiation, the composition rule holds, meaning \(v = v_1+ v_2 + ... + v_n\) with integer values for \(v_1, v_2, ..., v_n\). In general, this rule cannot be applied directly to semi integration or differentiation.
Oldham mention in his book [4] in chapter 5 the general properties of these semi operators, including the composition rule (ch. 5.7). Therein, he shows that for an arbitrary semi-integrable function the composition rule is not always necessarily applicable. The interested reader is referred to that chapter, especially table 5.7.2 and 5.7.3, which lists the restrictions of the composition rule.
The implemented algorithms need to be tested with multiple compositions of \(v\). In the following cases, the function \(y = 1\) (const) will be used, the numerical integration is taken as reference and a fixed step size of \(1000\). For these tests the limitation range for v has to be considered. For the Gruenwald algorithm is the range \(-1 < v < 0\) and only variations of v can be considered, which add up to a total of \(-1\) (‘full’ integration), e.g. \(v1 = -0.1\) and \(v2 =-0.9\). As the Riemann algorithm in its current implemented state only allows \(v=-0.5\) and 0.5, it will not further be considered in this testing.
Case 1: Double Semi Integration
As first test case the implemented algorithms will be applied twice with varying v values. Under consideration that v= v1 +v2 = -1 holds, v1 varies from -1 to 0 and v2 from 0 to -1, both in 0.001 steps. The following figure shows a double logarithmic plot of the relative error along the v1 (or v2-1) values for the Gruenwald algorithm. It can be seen, that all errors are near the machine precision, which means the algorithm can be used in that way.
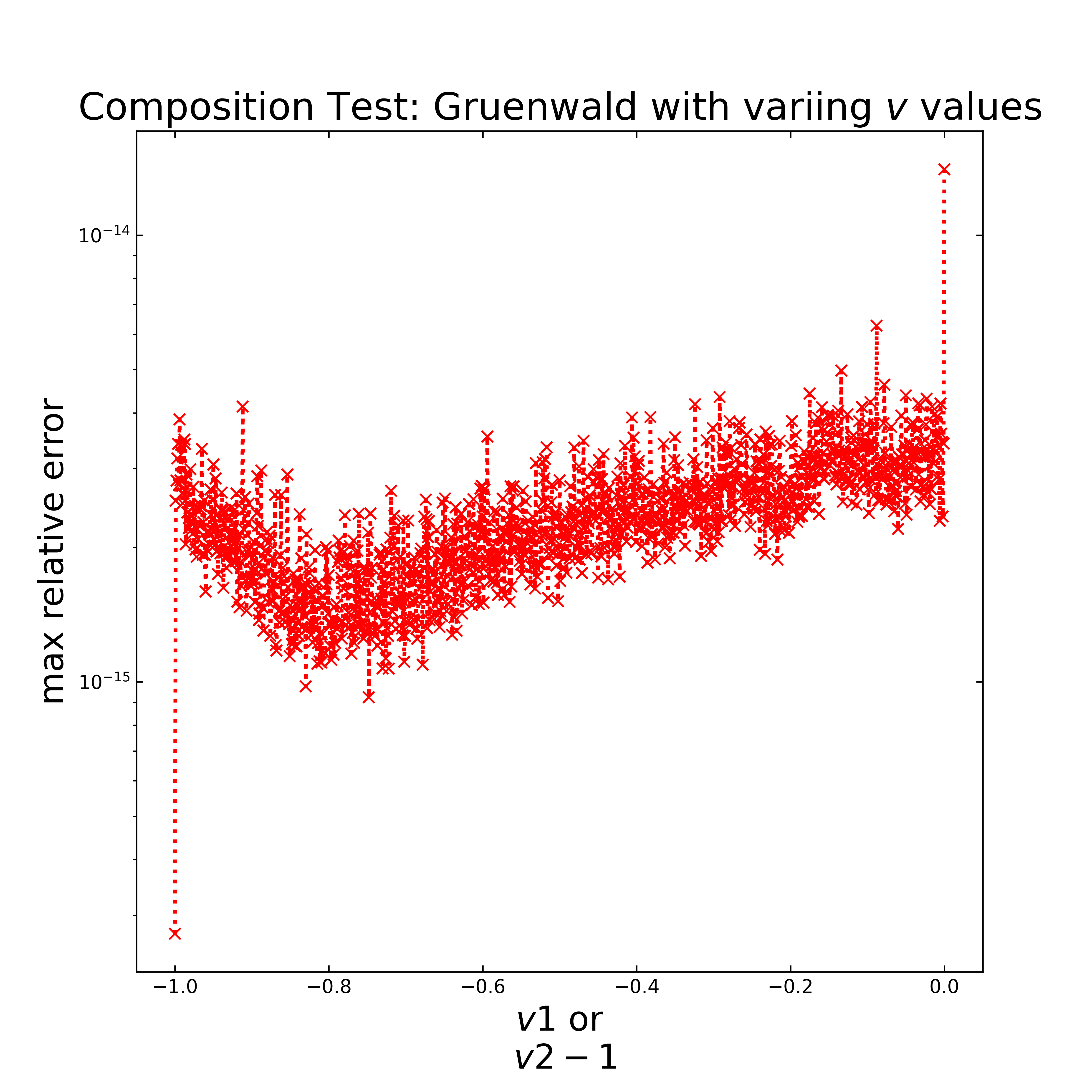
The same setup is tested for the implemented fast Riemann algorithm and is displayed in the next figure. Here, the relative error is lowest for \(v_1=v_2=-0.5\), which is reasonable, as it was optimized for electroanalytical applications [5]. Compared to the Gruenwald algorithm, the relative error is overall quite high, but similar to the previous testing, the accuracy is related to the number of steps (here \(1000\)).
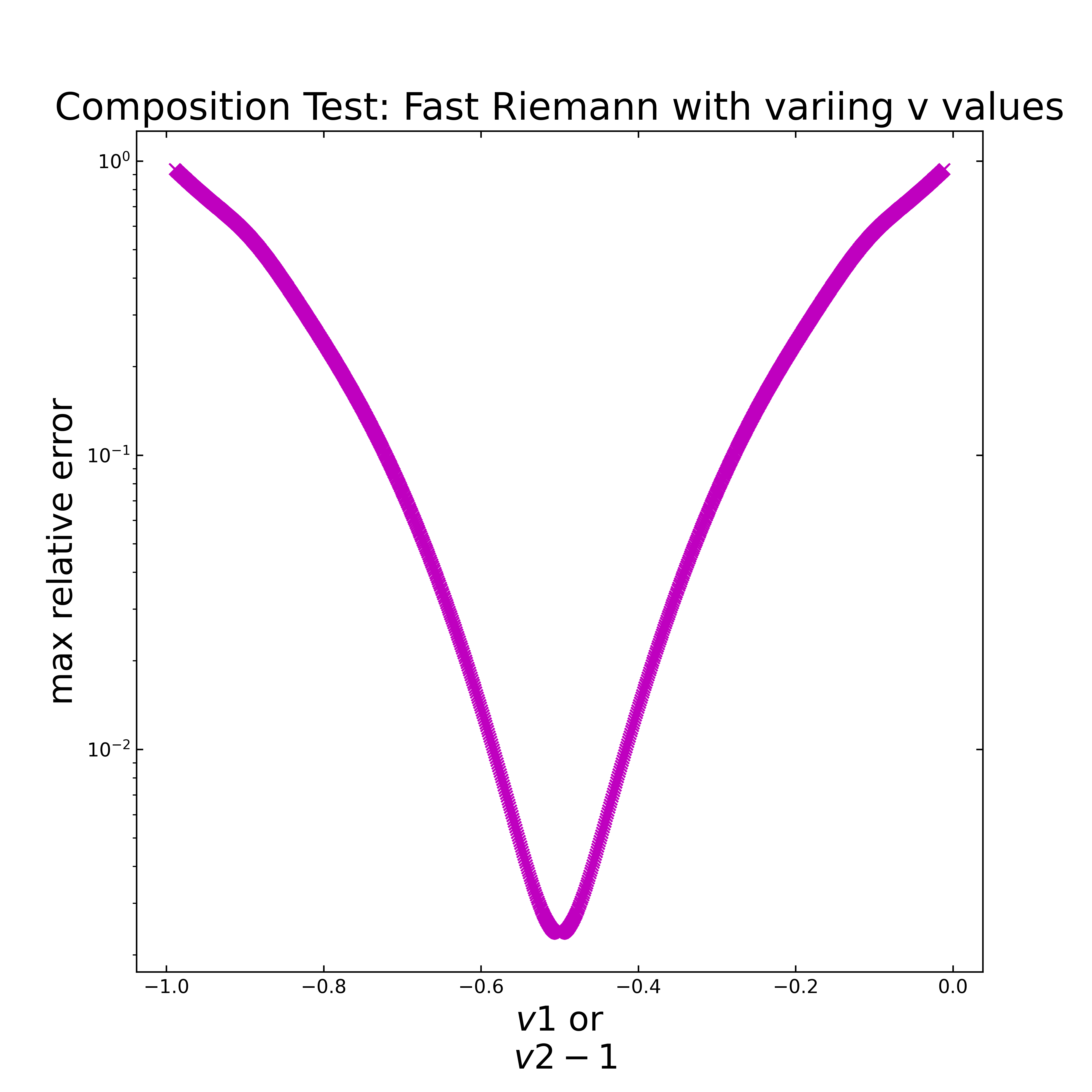
Case 2: Triple and more Semi Integration
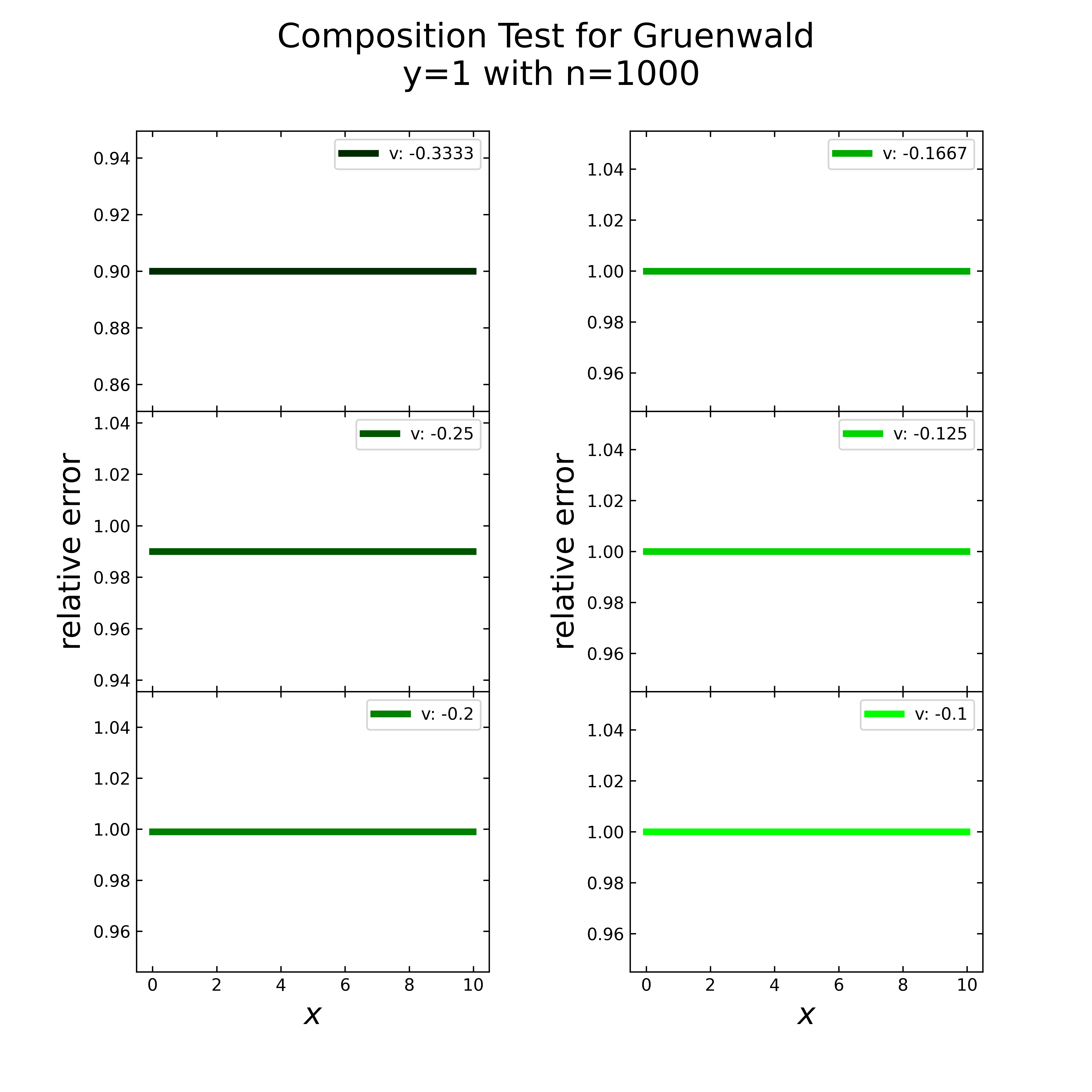
The previous case considers only the application of semi integration to times (e.g. with \(v1, v2=-0.5\)). Now it should be checked whether triples and further compositions are possible. Both, the Gruenwald and the fast Riemann are applied for the following six scenarios: 3 times (\(v=0.3333\)), 4 times (\(v=0.25\)), 5 times (\(v=0.2\)), 6 times (\(v=0.1667\)), 8 times (\(v=0.125\)) and 10 times (\(v=0.1\)).
The following figure shows for each mentioned scenario the relative error along the x- values for y=1 (const) with \(1000\) steps. Here it is obvious, that the error is every time at a constant value (near 1), i.e. the application is not plausible.
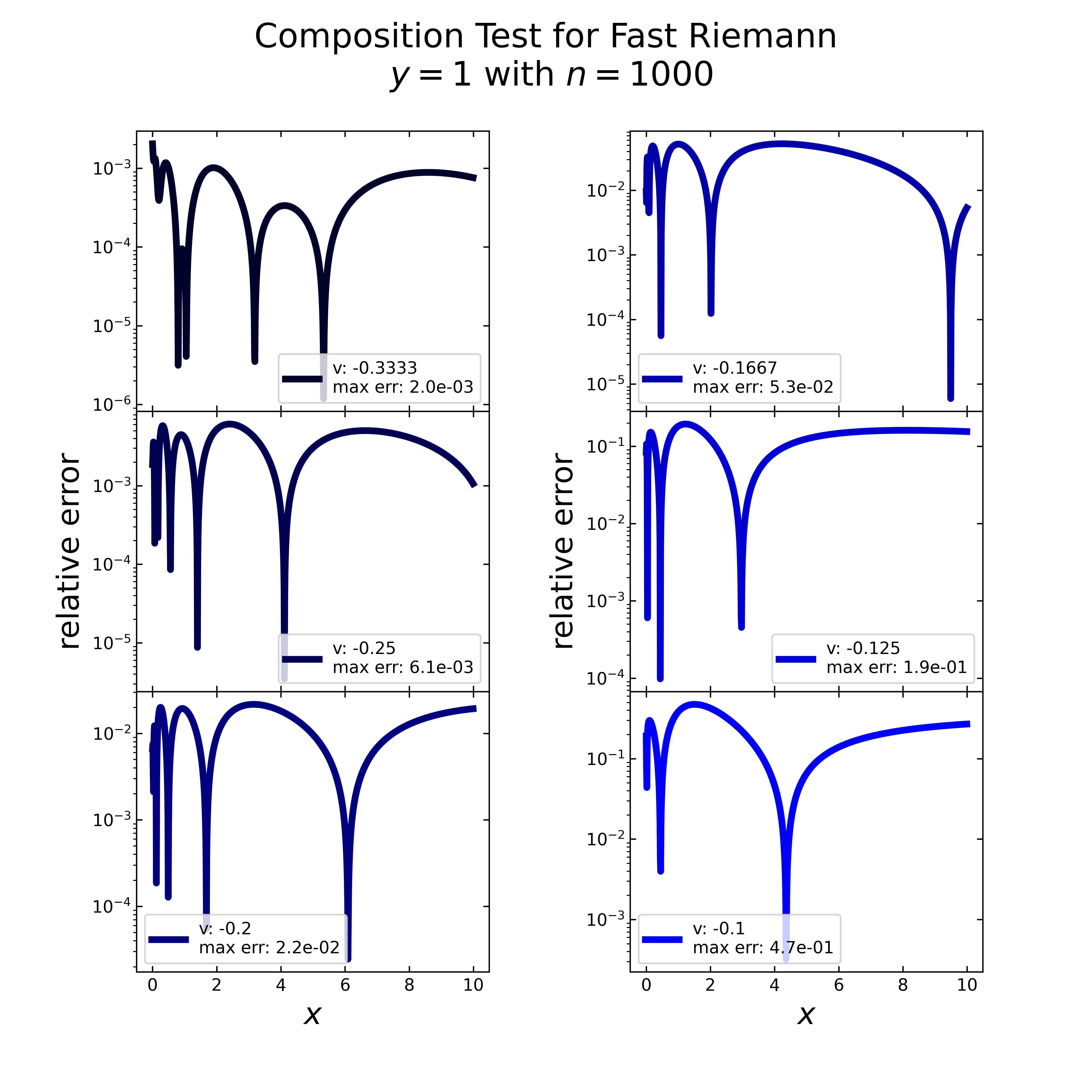
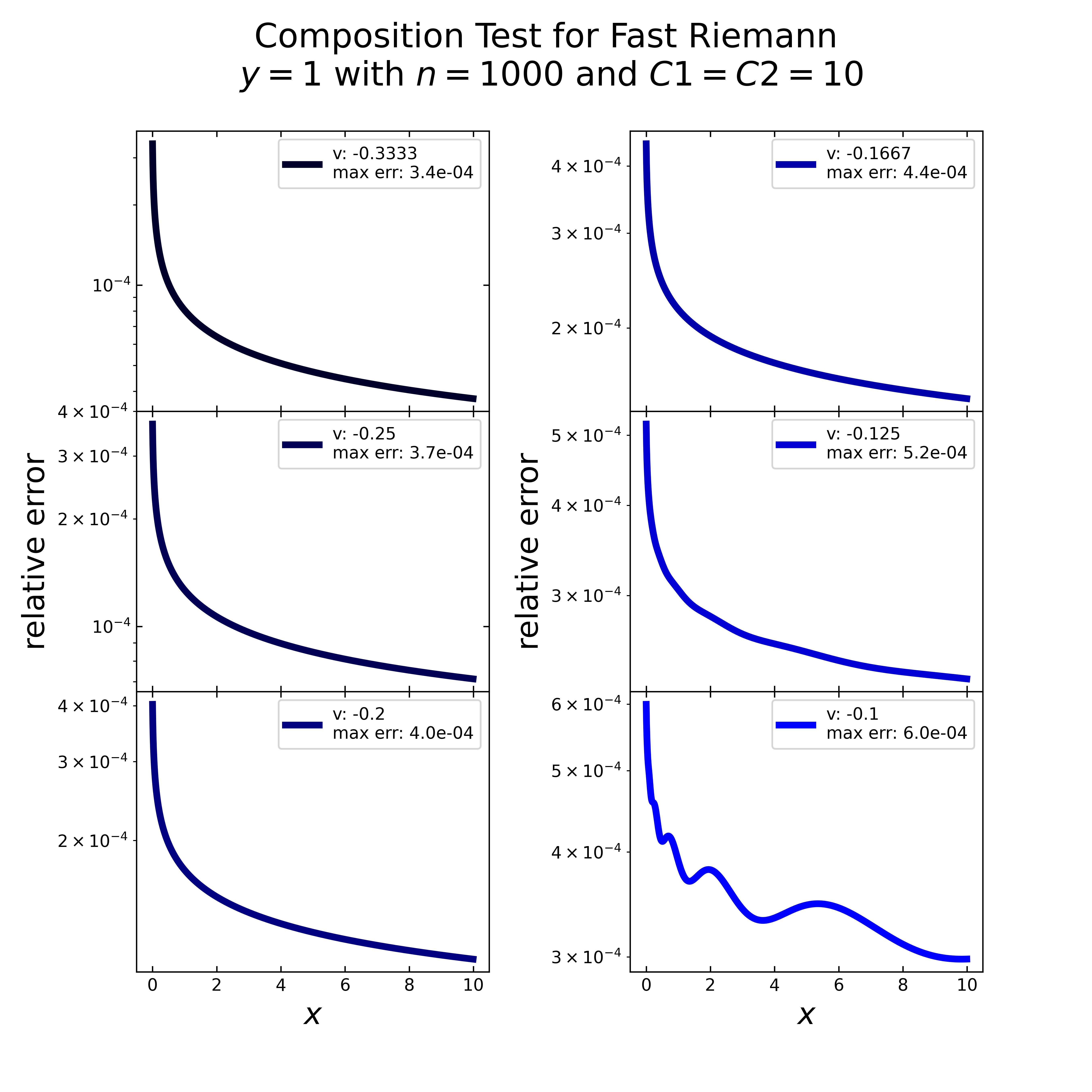
Focused on the fast Riemann, the next image displays the relative error (here logarithmic) for the same case (\(y=1\), \(n=1000\)). For each scenario, there are multiple inverted peaks, similar to the previous tests, which makes the overall error not valid.
The last composition test considers the fast Riemann again, but now with modified \(C_1\) & \(C2\) values (\(10,10\)). Here the resulting relative errors (figure below) don’t show anymore the inverted peaks. Except the last scenario, all others errors decrease steadily. Latter one shows slight disturbances, but still a decrease. All scenarios with the modified C values show quite reasonable errors (below \(-10^{-4}\)), therefore a further investigation of these \(C\) values is necessary.
Performance Test
The performance test is intended to provide an insight into the required computing time for the implemented algorithms. Beside the direct call of each implemented algorithm, a generalized call with the implemented “semi_integration” function allows to speed up the calculation with the help of the transonic package. This allows three different backends: Python, Numba and Pythran.
In the following, the gaussian distribution was taken as input data and varying step size. The numerical integration (cumulative trapezoid) from the Scipy package was taken as reference. The following image displays the consumed time for each algorithm and the chosen backend in dependence of the number of elements (No. of step size).
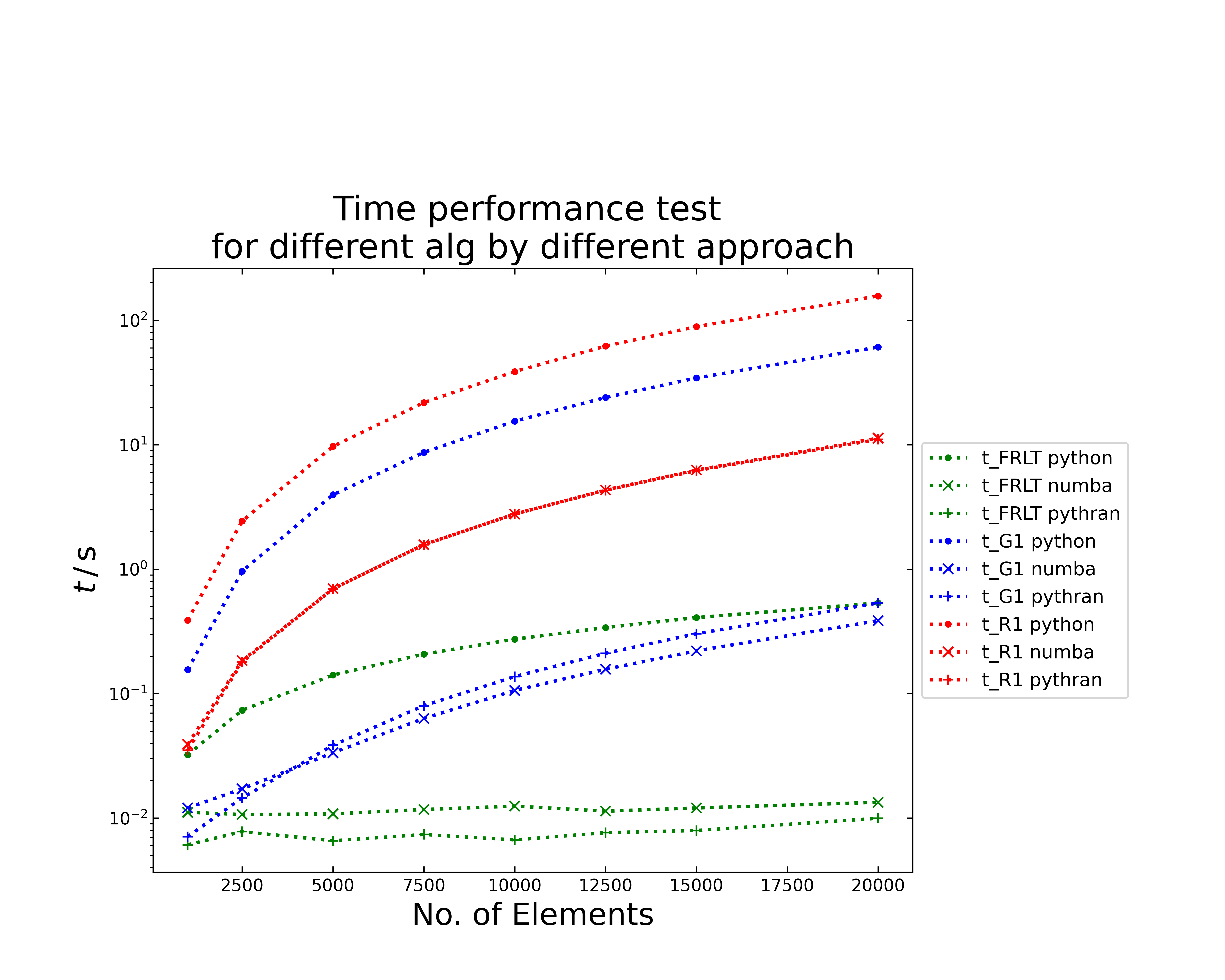
The time performance plot displays semi logarithmic the required time for the algorithm of Riemann (red), Gruenwald (blue) and for fast Riemann (green). The symbols define the chosen setting, i.e. with transonic backend Python (dot), Numba (cross) or Pythran (plus).
The Riemann requires with all implementations the longest computation time, while the Gruenwald shows a better performance. Here the application of the numba and pythran backends allow to decrease the time up to two orders of magnitude, compared to the python backend. The fast Riemann shows the best performance and especially with the numba and pythran backend it seems to have nearly no time increase with the chosen element sizes.
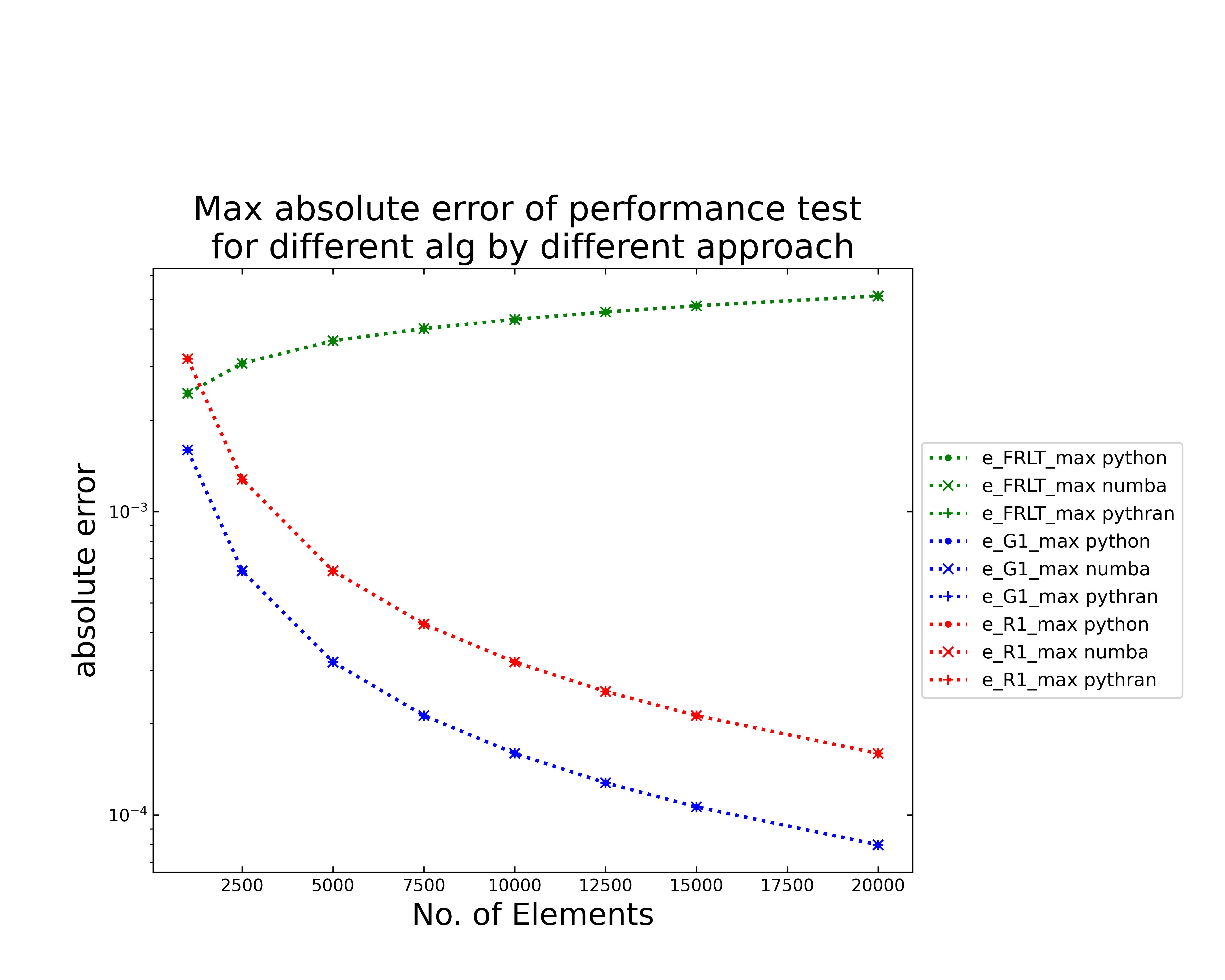
The next figure (above) shows the evolution of the maximum absolute error for each algorithm in a semilogarithmic plot. Here the color and symbols correspond to the ones in the time performance test. Generally, the calculated error should only depend on the algorithm and not on the chosen setting, which can be seen in the plot. The fast Riemann shows an increasing graph with the highest error, similar to the accuracy tests. Both, the Gruenwald and the Riemann show a decreasing absolute error. Related to that shows the Gruenwald the best absolute error behavior. Now it is still necessary to consider the relative error.
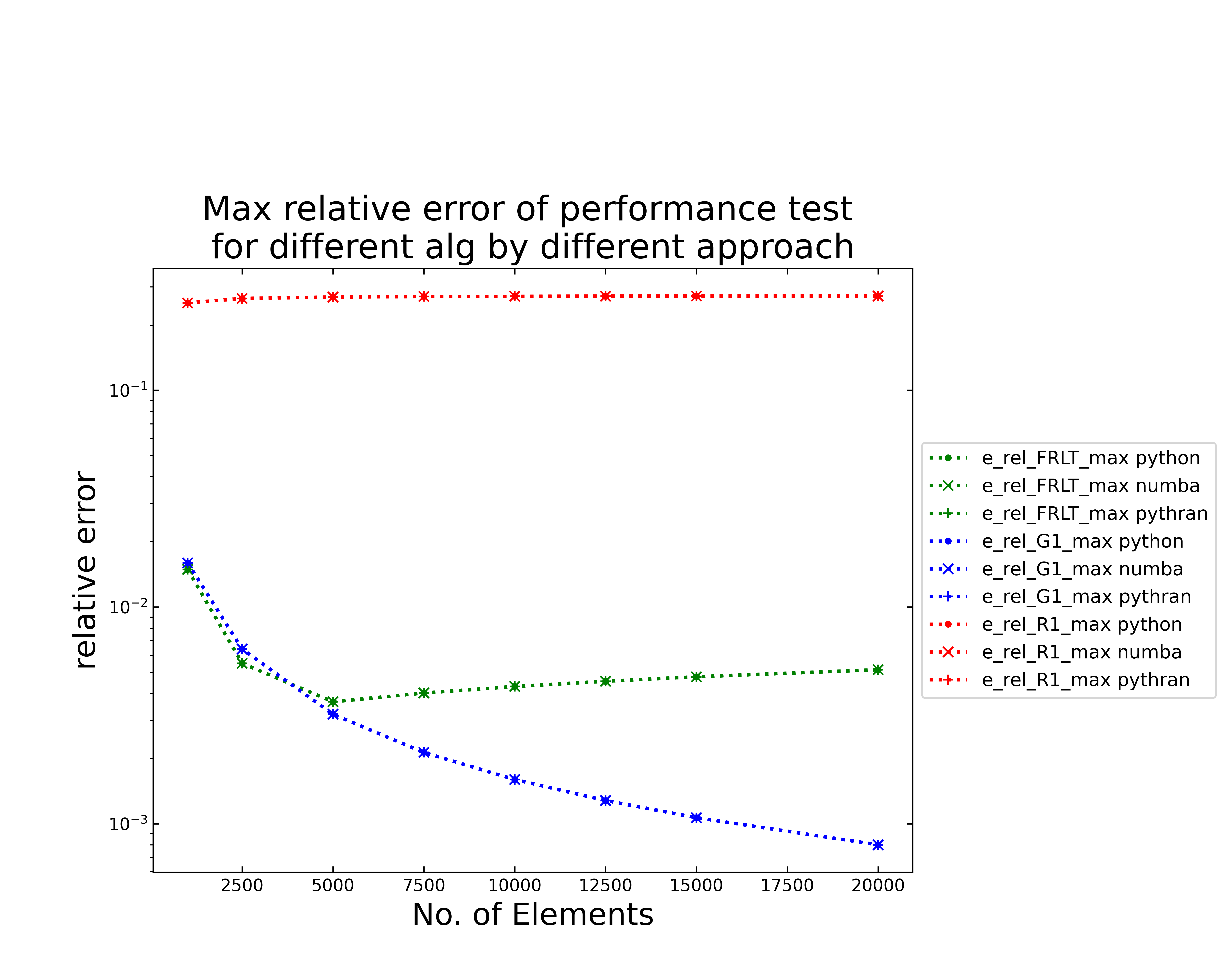
Therefore, the figure above shows the maximum relative error plotted semi logarithmic along the number of elements. Colors and symbols still contain the same algorithms and settings. The relative error depends, similar to the absolute error, only on the chosen algorithm. The Riemann shows the worst error, as already observed in the accuracy test. The absolute error of the fast Riemann shows a much lower error, which decreases up to \(5000\) elements and then increases slightly. The Gruenwald implementation shows the smallest relative error, which decreases with increasing elements.
References
Richard Dedekind and Heinrich Martin Weber, editors. Versuch einer allgemeinen Auffassung der Integration und Differentiation. (1847.), pages 331–344. Cambridge University Press, 1 edition, October 2013. doi:10.1017/CBO9781139568050.020.
AK Grünwald. Über "begrenzte" Derivation und deren Anwendung. Z. Angew. Math. Phys., 12:441–480, 1867.
Keith B. Oldham, Jan C. Myland, and Alan Maxwell Bond. Electrochemical Science and Technology: Fundamentals and Applications. Wiley, Chichester, reprinted with corrections edition, 2013. ISBN 978-0-470-71085-2 978-0-470-71084-5 978-1-119-96588-6 978-1-119-96599-2.